An open-source framework that provides a
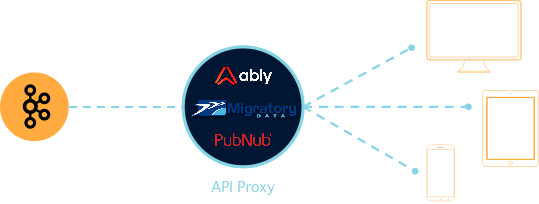
real-time API Proxy for Kafka
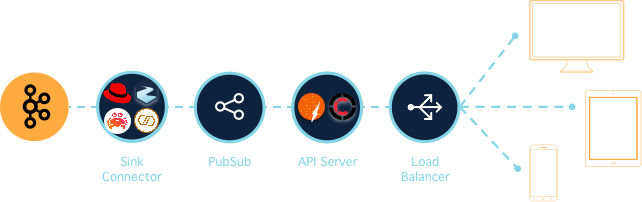
Real-time Streaming from Kafka
Real-time Streaming from Kafka
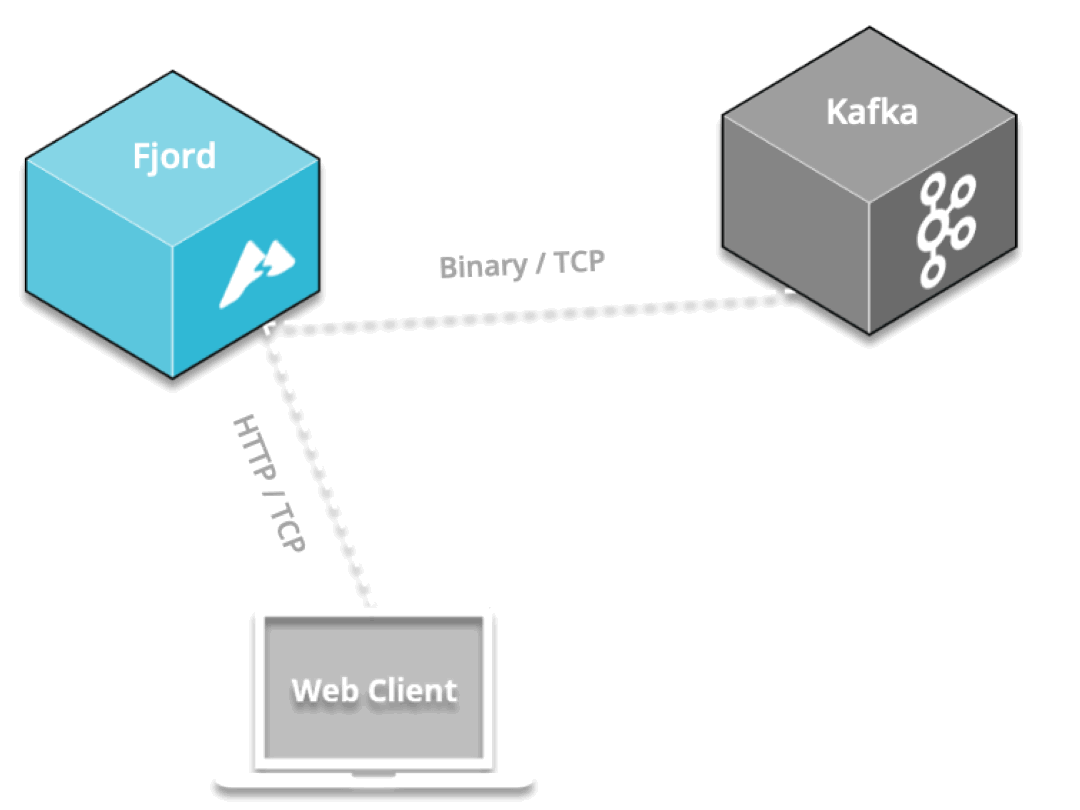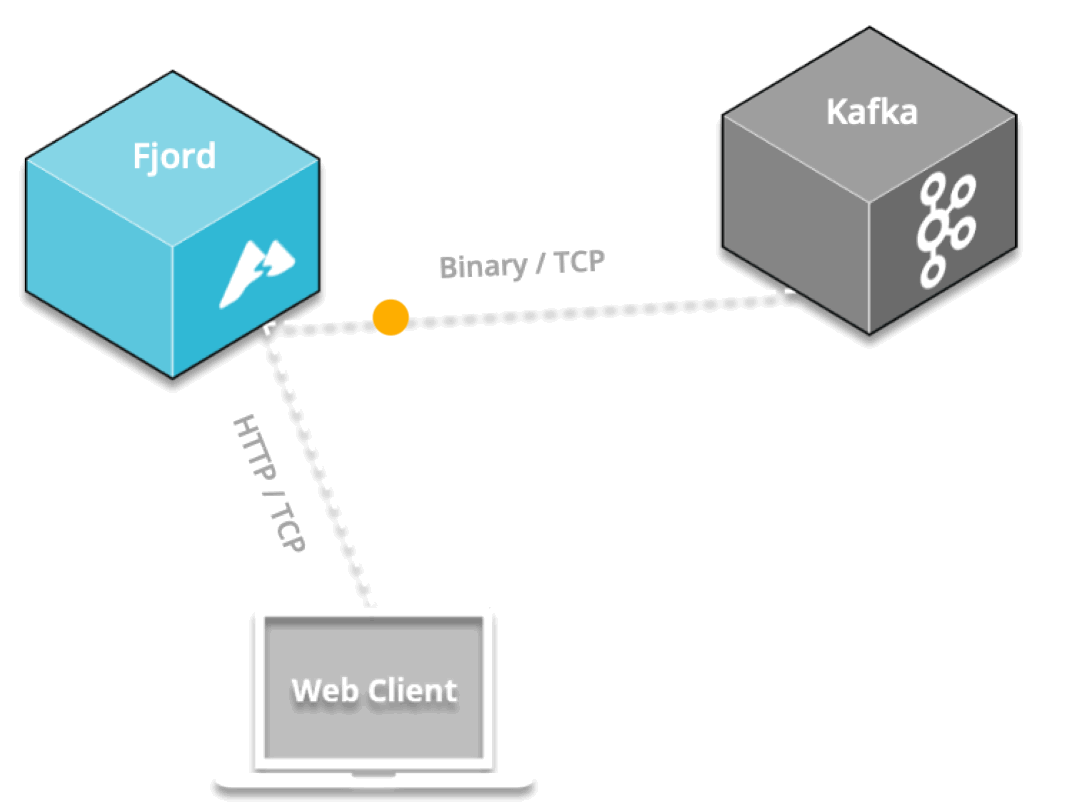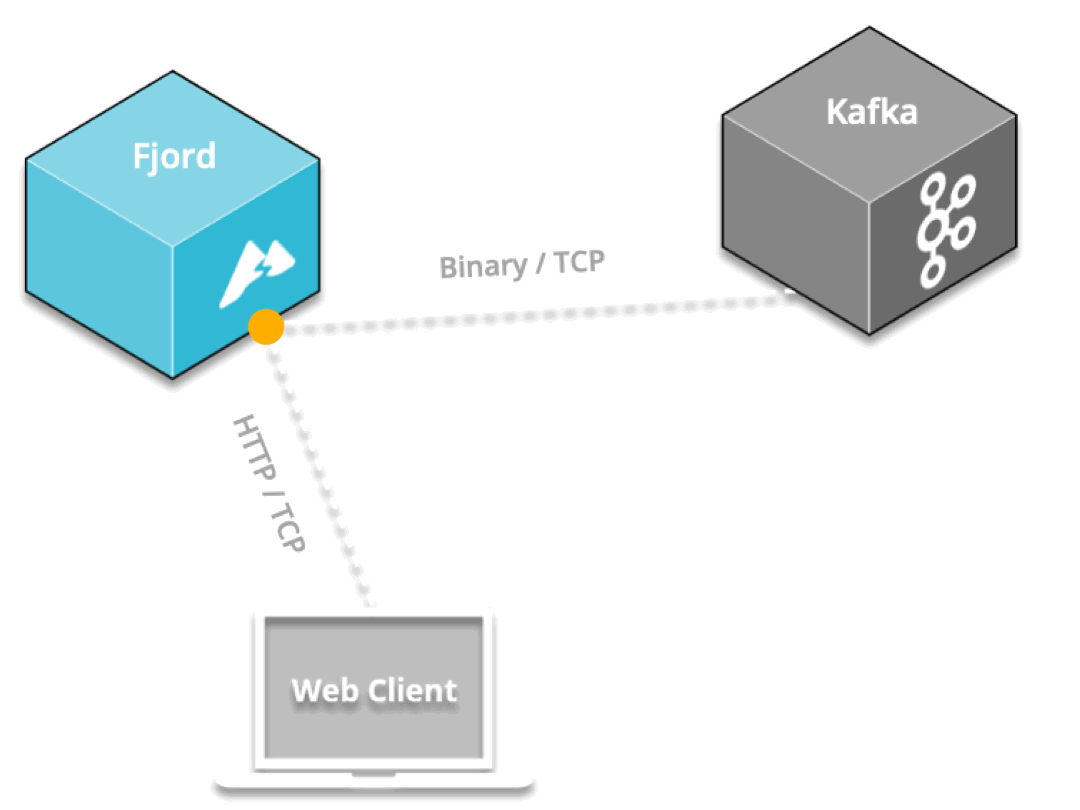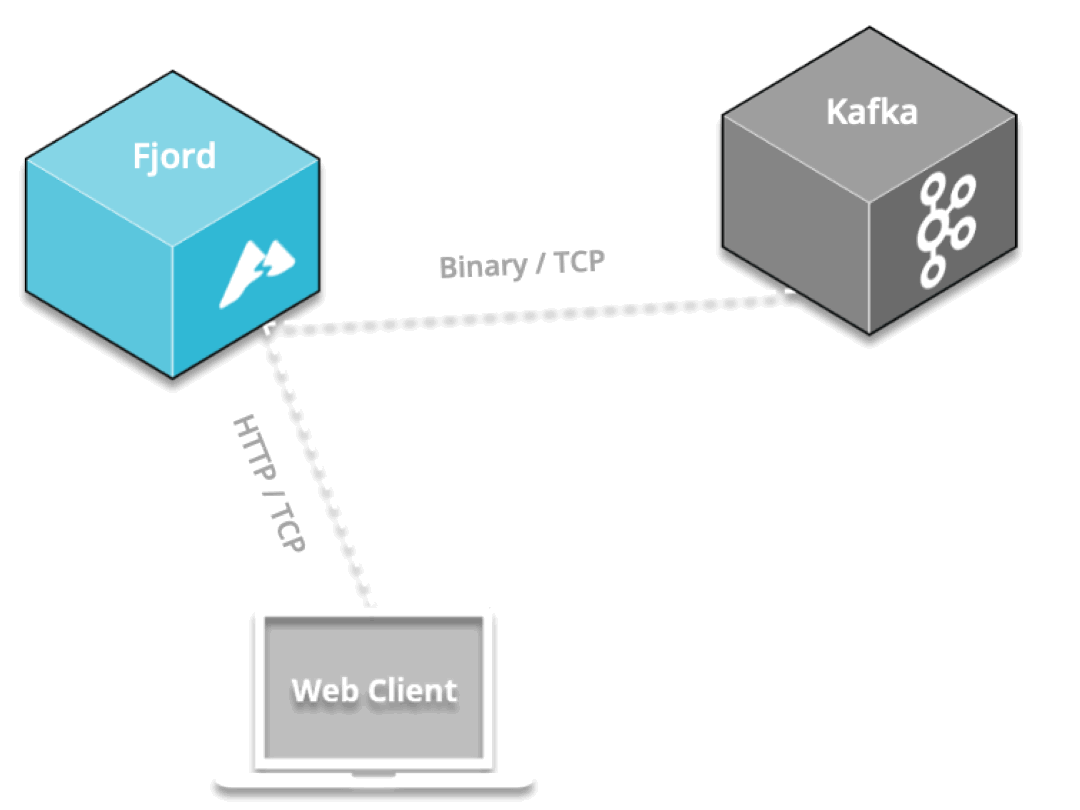
Fjord exposes real-time API endpoints to allow internet-facing clients to stream from Kafka
Easy To Deploy
Easy to Deploy
Use Fjord's CLI to deploy all the necessary infrastructure
to Amazon Web Services (AWS).
Scalable Infrastructure
Scalable Infrastructure
Fjord's infrastructure automatically scales up and down based on demand.
Case Study
1. What is Fjord?
Fjord is an open-source framework that enables client-side streaming from Kafka in real-time.
Through Fjord’s CLI, developers can easily and quickly deploy dozens of components on Amazon Web Services (AWS) to offload the streaming responsibilities to Fjord’s scalable real-time API proxy infrastructure.
This enables any number of authorized end users--whether on a browser or a mobile app--to receive data streams from any number of Kafka topics from any number of Kafka clusters.
In this case study, we outline the key challenges we faced as we worked with real-time APIs, event driven architectures, and Kafka as an event streaming platform.
2. Use Case & SuperEats example
2.1 Who Might Use Fjord?
Any company or organization that uses Kafka may need to expose one or more Kafka topics to a client interface, whether because this is a central or tangential aspect of their business, or even just as an additional layer of human observability into a particular data stream.
Building, hosting, and managing the infrastructure necessary to handle client-side
streaming from Kafka can be challenging, time consuming, and the kind of undifferentiated heavy lifting that is best outsourced to a third party.
We see our target user as an organization that:
Is large enough to already use Kafka for some aspect of their infrastructure,
Wants to expose some stream of data (i.e. from a Kafka topic) in real-time to their employees, customers, suppliers, or any other type of stakeholder, including the public at large--or any combination of these.
Of course, this organization is cost-conscious and wants the most efficient and easy way to deploy the infrastructure needed to solve this problem, while still managing, owning, and closely handling all the data themselves.
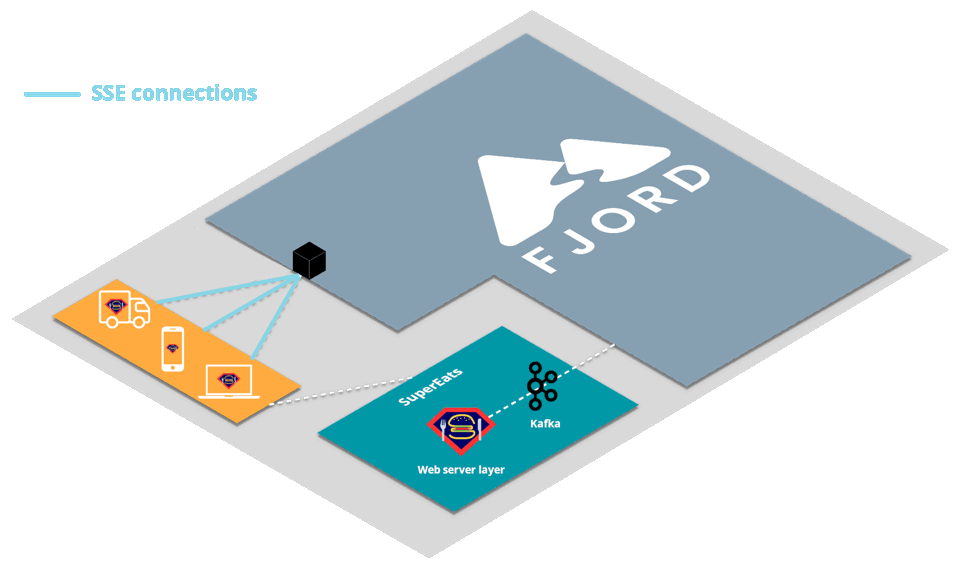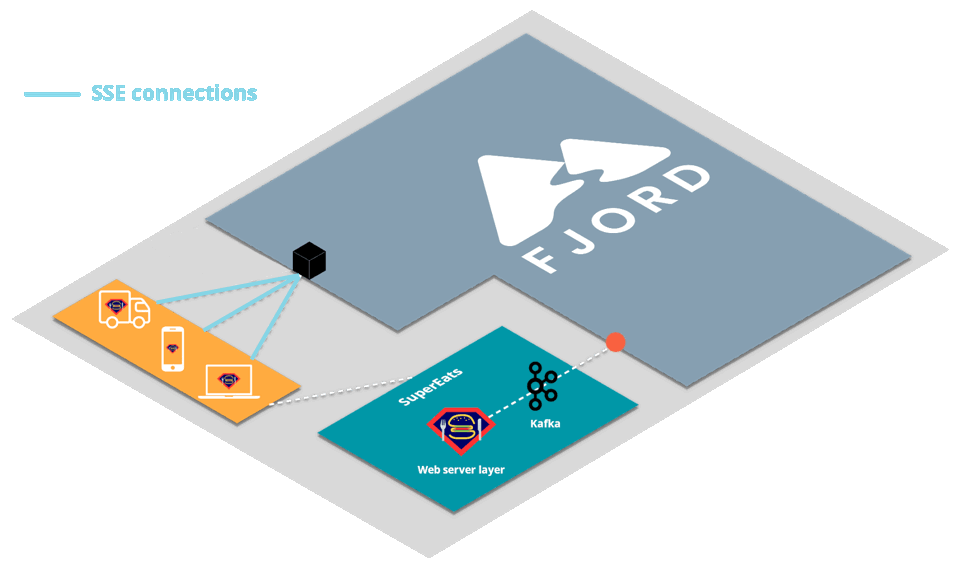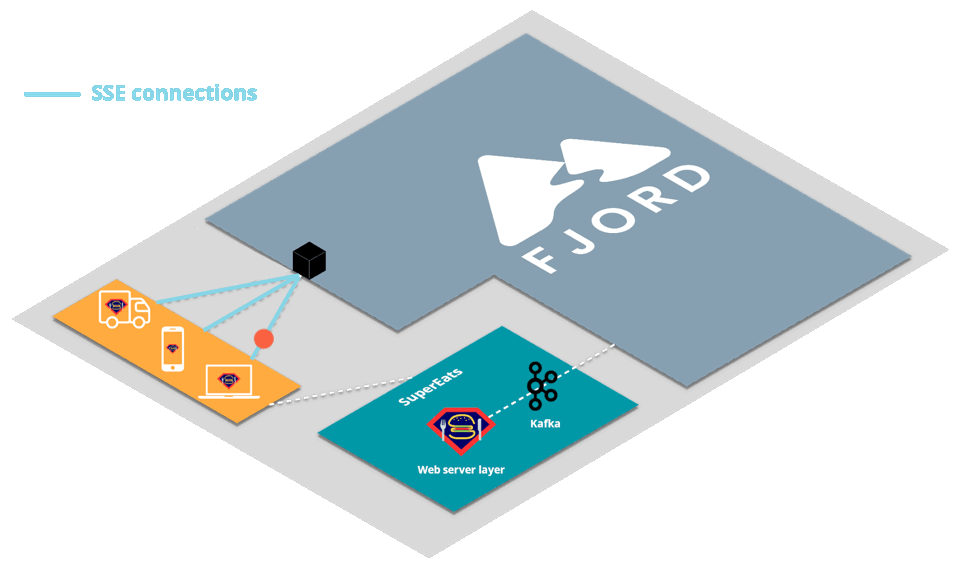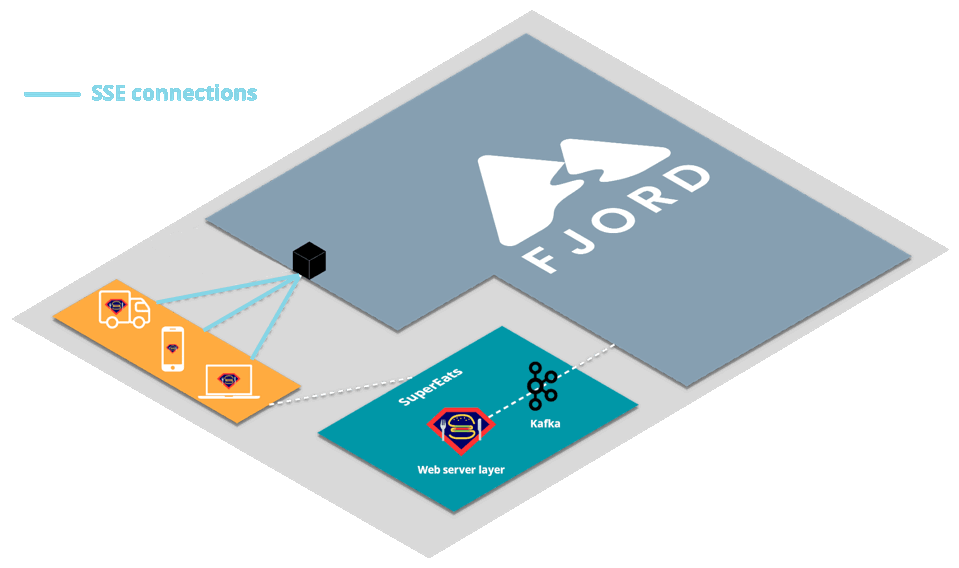
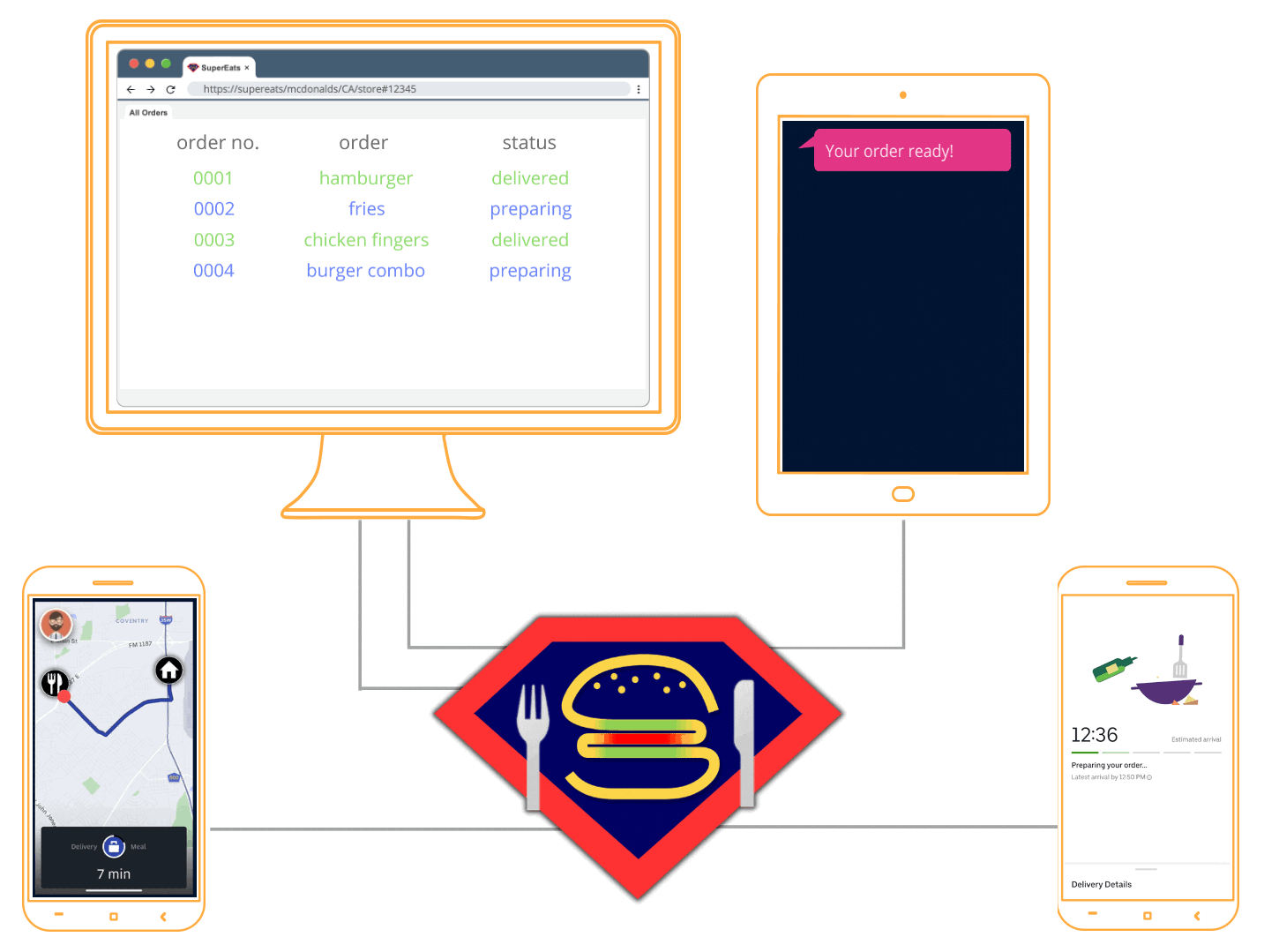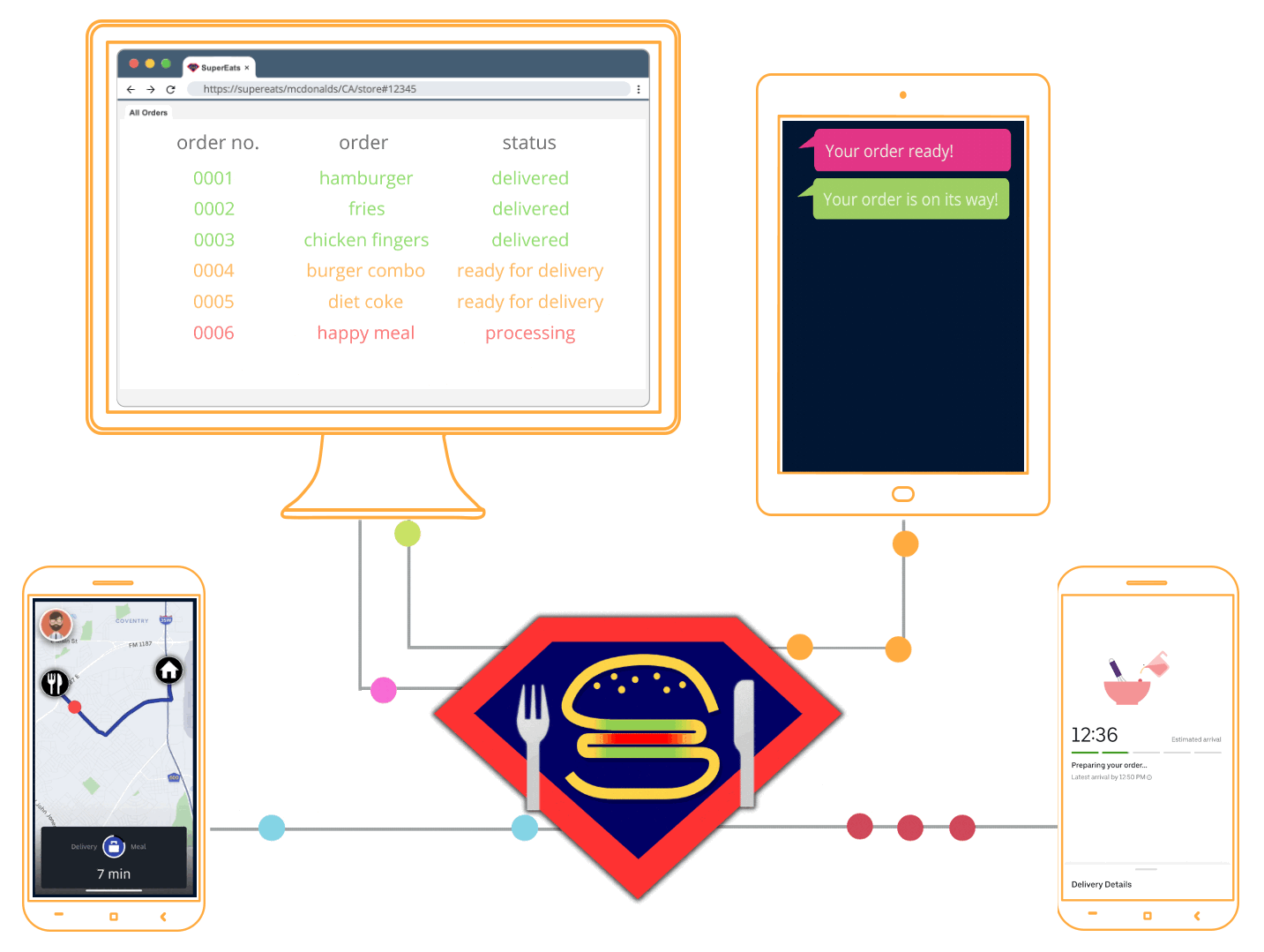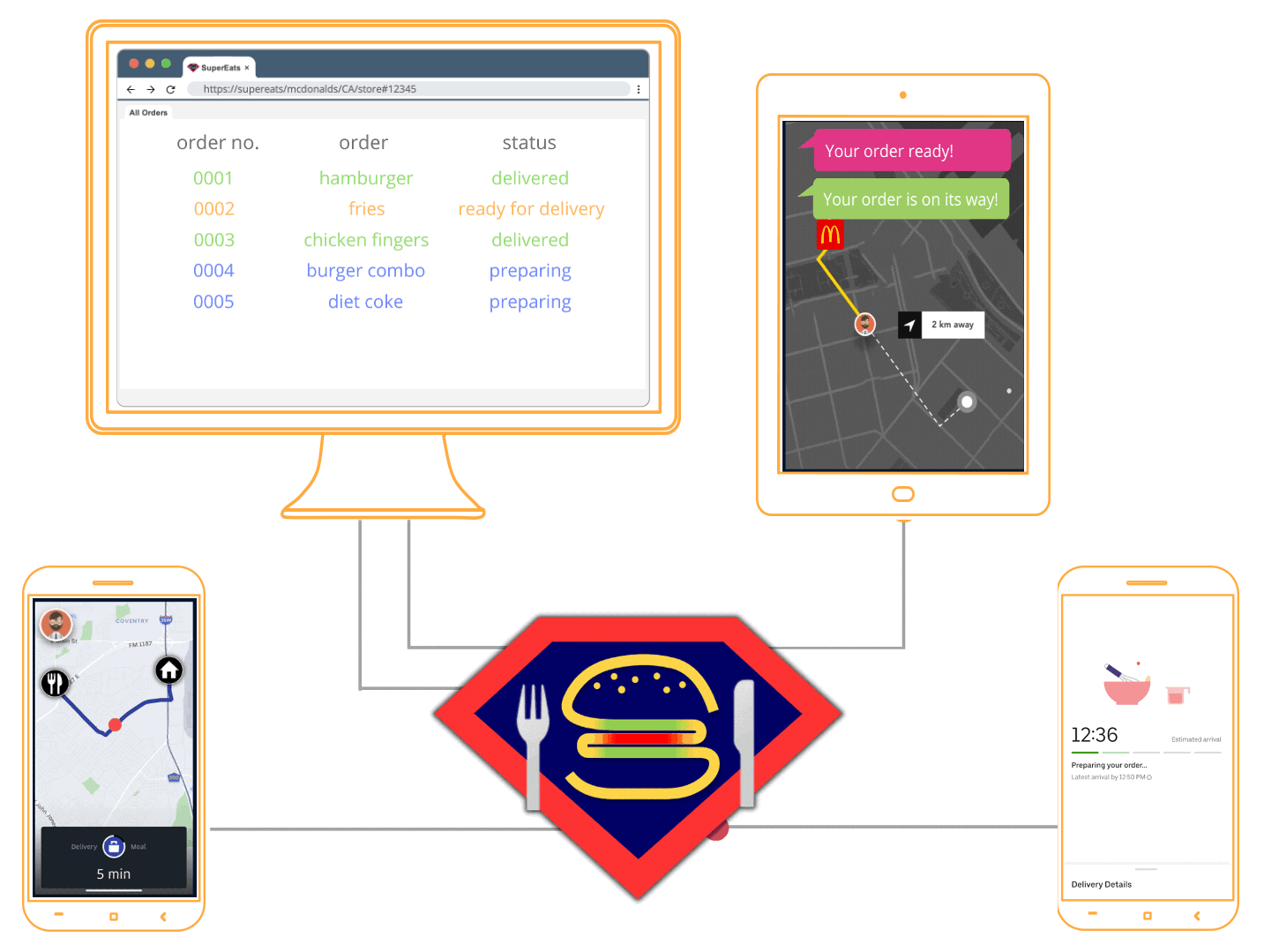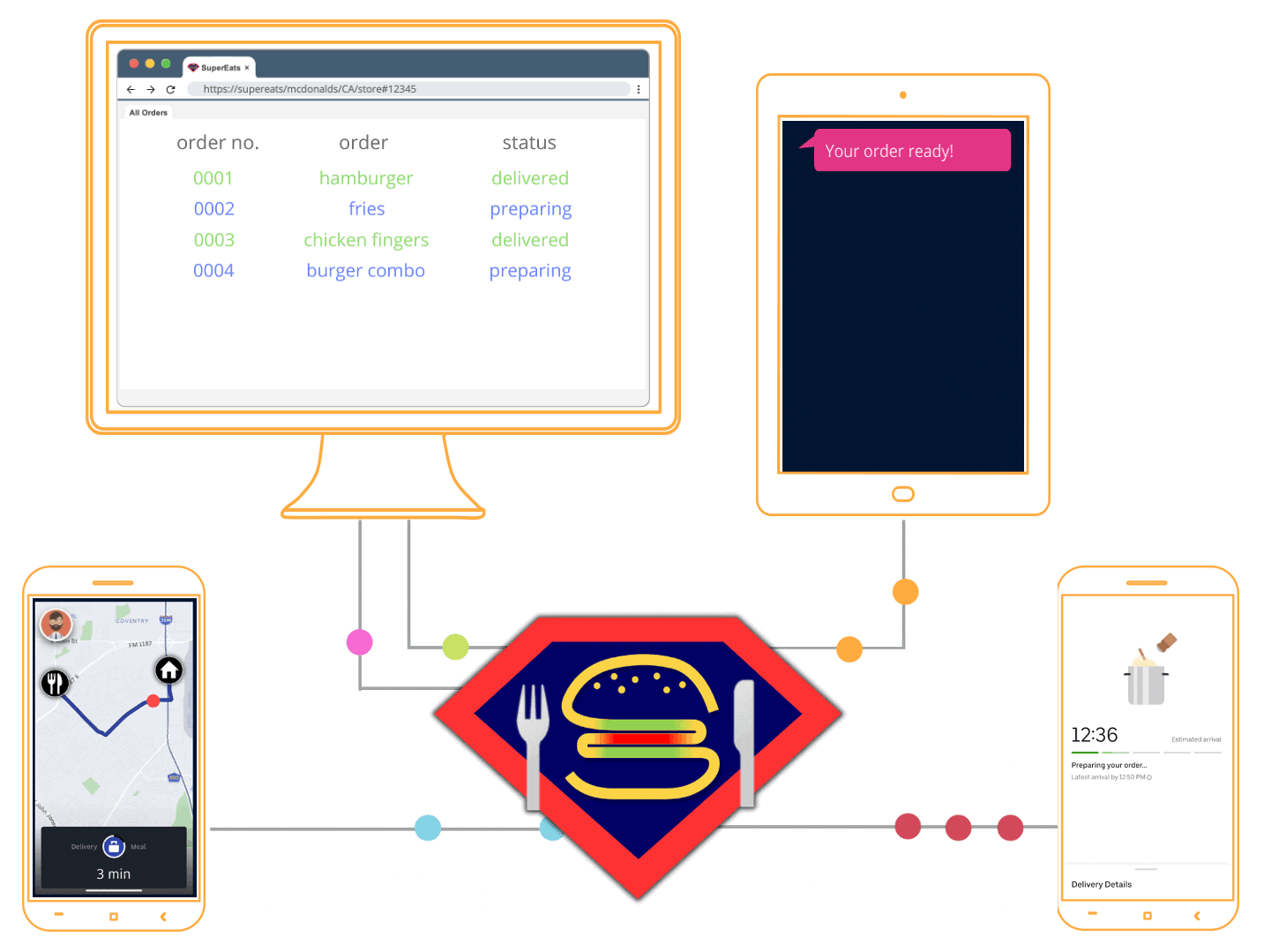
2.2 SuperEats Example
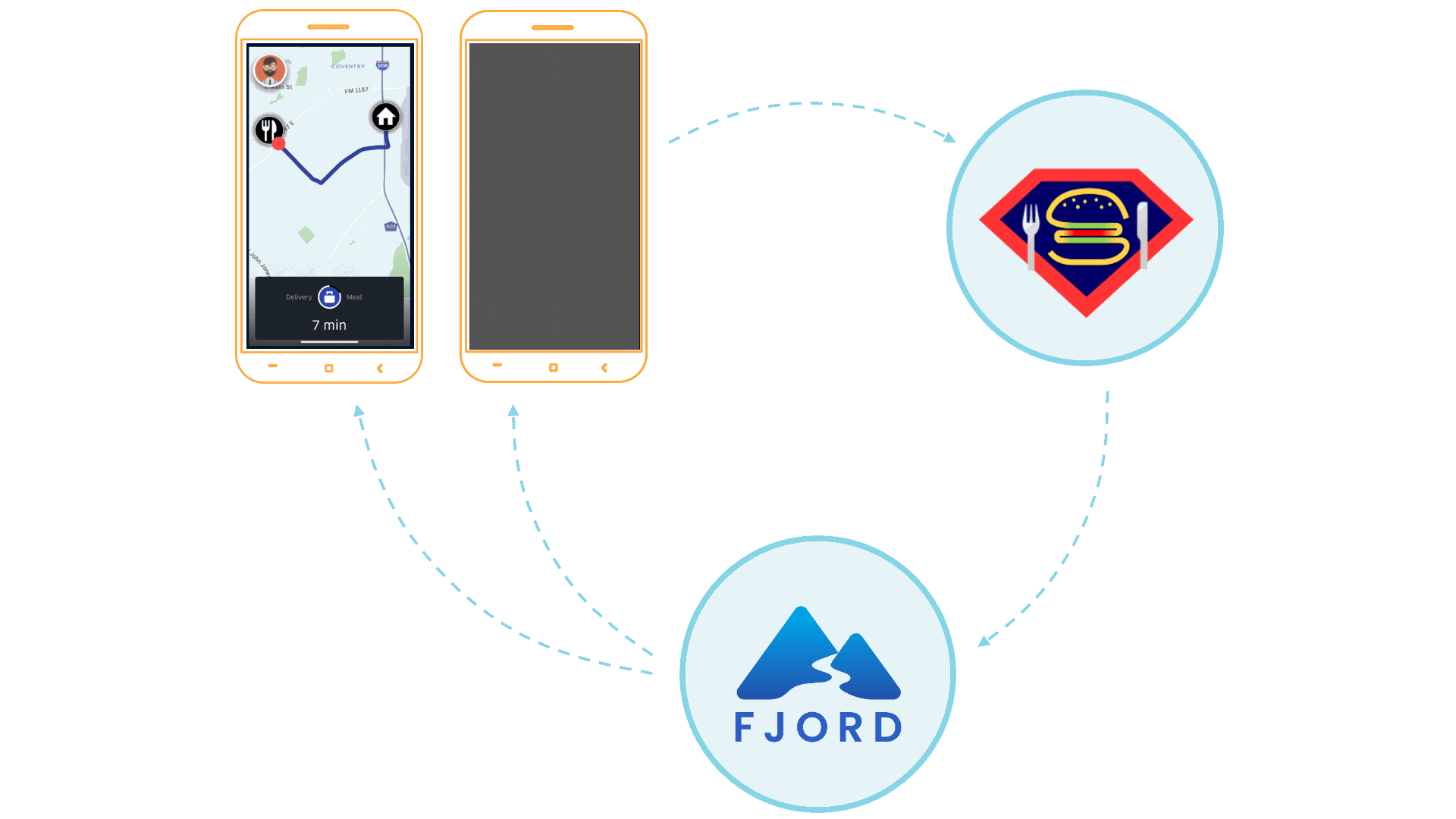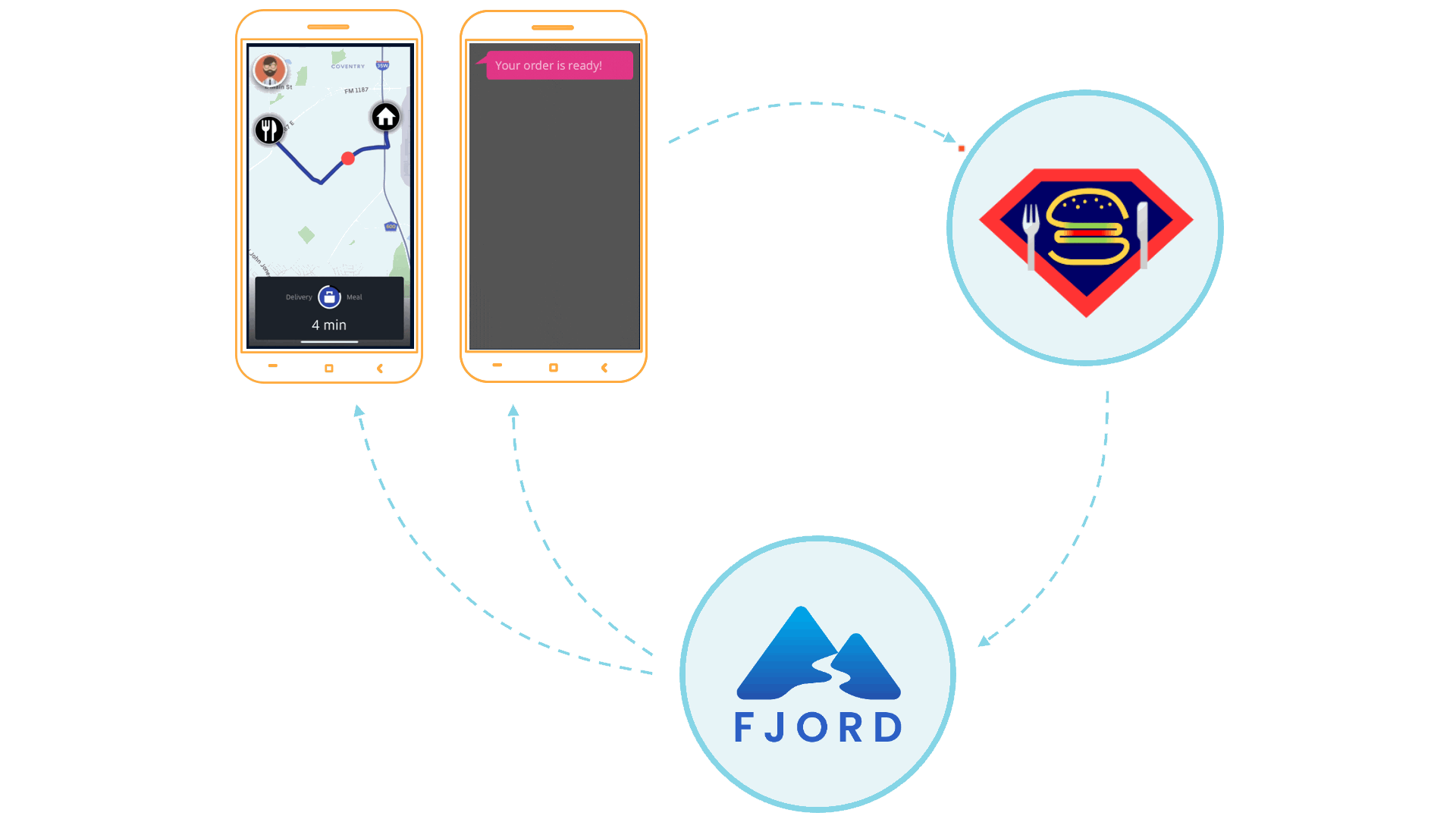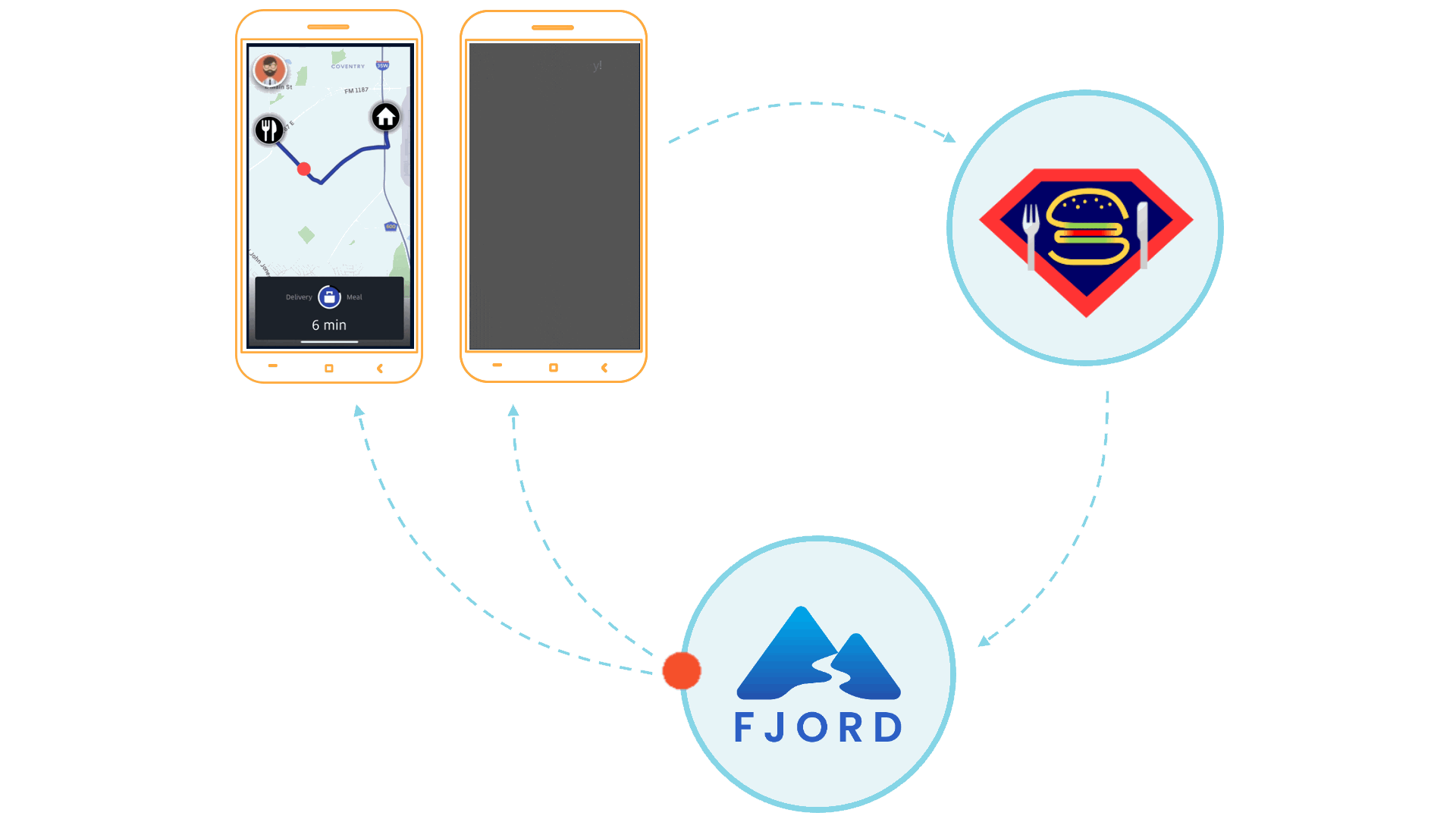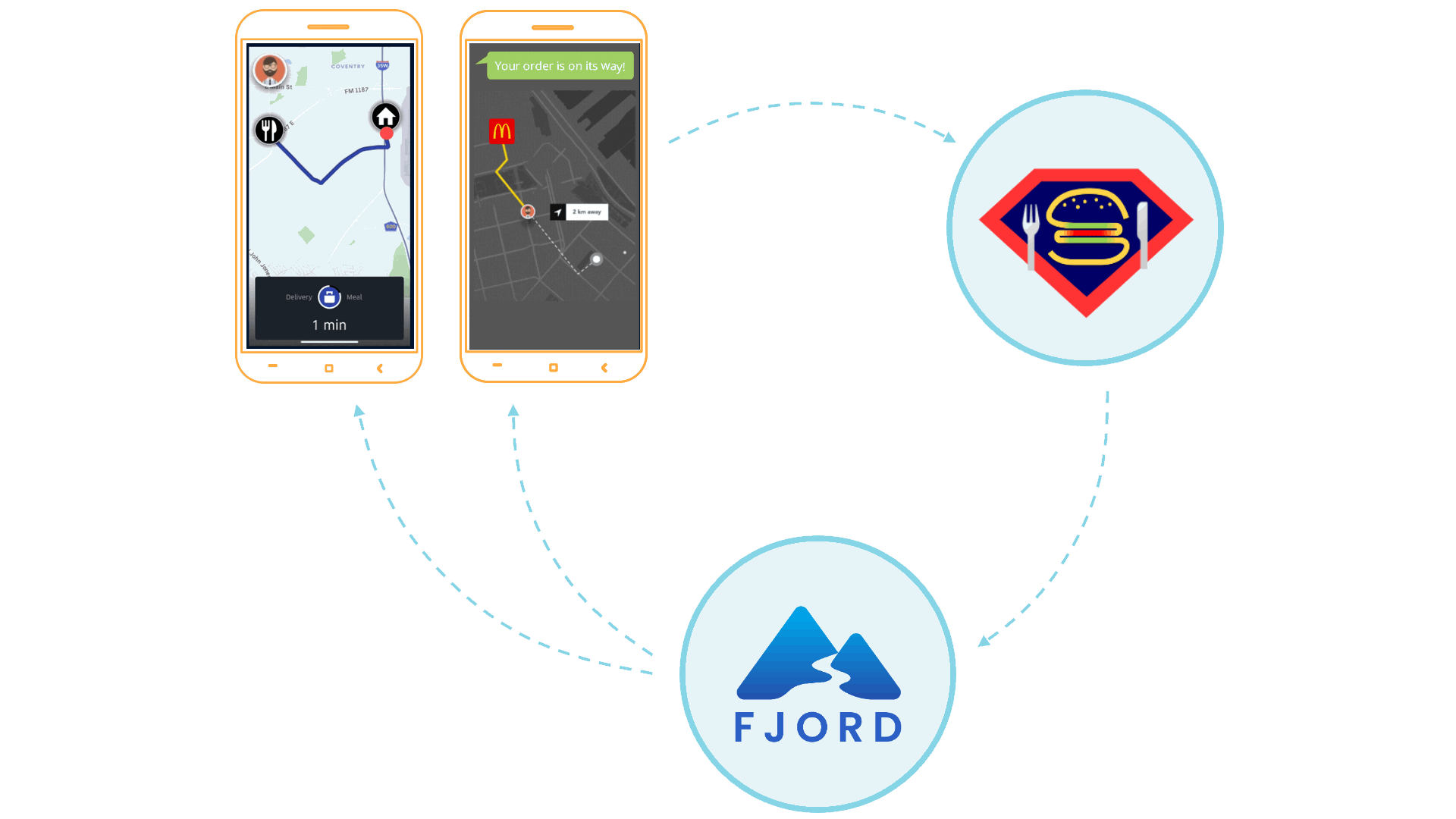
Let’s imagine that you run a company called SuperEats. Your company provides a platform that enables customers to order a meal from any registered restaurant, and independent contractors to pick up the order from that restaurant, and drive the meal to the customer.
SuperEats works with thousands of restaurants, from well-known multinational chains like Chipotle to small hole-in-the-wall shops like Cousin Vinny’s Hot Dogs. Customers place an order from their favorite restaurant, which then comes into SuperEats’ Kafka cluster.
You want your platform to then not only send orders out to drivers, but also for customers to receive real-time updates at every step of the way. For example, customers should know when their meal was made, when the driver has picked it up, when the driver is about five minutes away from their home, and finally when their meal is at their doorstep.
To accomplish this, SuperEats needs a real-time infrastructure that is secure, easy to deploy and use, and takes advantage of their existing infrastructure.
3. What is Real-time?
3.1 Defining Real-time
Ably, a leader in the real-time space, defines real-time thus:
Real-time is the ability to react to anything that occurs as it occurs, before it loses its importance.
This definition illustrates the main idea here: within the context of web applications, the goal of real-time streaming is to allow the recipient to get the information they need within sufficient time to adequately respond to it.
Restaurants expect real-time updates on orders as soon as they are placed by customers. Customers expect updates on their order status, and drivers are constantly on the look out for nearby delivery requests.
If any of these groups aren’t able to get updates in real-time, their user experience is degraded, and updates would no longer be meaningful.
3.2 Real-time Techniques
There are different techniques developers could use to deliver real-time updates over the web.
3.2.1 Long polling
With long polling, the client sends an initial HTTP request to the server, and the server then waits until there’s a new piece of data to send back. Once the server gets a new update, it sends a response and immediately closes the request. The client must then send yet a new request to receive another update from the server.
This is great in situations when the rate of new message production is not high. For example, the current outdoor temperature usually doesn't significantly change every quarter or even hour.
There are downsides to using long polling. Having the client send a new request and the server send a new response for every single new message not only adds more latency to the process, but also puts more work on both the client and the server.
3.2.2 Server Sent Events (SSE)
SSE (also known as EventSource) is a web API that enables a client to receive a continuous stream of data from a server.
The client sends an HTTP request through the EventSource WebAPI, which lets the server know this request is for a stream of data. The server then returns a never-ending HTTP response whose headers indicate that the connection will be ongoing until explicitly closed. At the same time, the server starts to send any data received, all in the same HTTP response.
Just like long polling, SSE is unidirectional. The data is only streaming from the server to the client, and not vice versa.
However, the SSE approach is much more efficient than long polling, as there’s no longer the need to continuously open and close HTTP responses for every message. All data is being transmitted through one never ending HTTP response.
SSE is therefore ideal for situations where the client is not regularly sending information to the server, but is instead receiving a constant stream from the server.
3.2.3 WebSockets
WebSockets is a protocol that allows a client and a server to repeatedly exchange data through a single TCP connection. This bidirectional protocol means that both the client and the server can send data to each other as long as the WebSocket connection remains open.
The client first sends a normal HTTP request, but this request contains headers that ask the connection to be upgraded to a WebSocket connection. The server then sends a response that opens the bidirectional communication line over the WebSockets protocol.
WebSockets are great in situations where both the server and the client need to frequently send data to each other, such as in online gaming and chat room applications. WebSockets are also seen as the de facto technology for real-time communication, which means that there’s a large community available for support, and many open source libraries available.
3.3 Choosing a Real-time API
3.3.1 Unidirectional v.s. Bidirectional
SSE’s unidirectional limitation was not an impediment in our use case. Our goal was always to stream content from Kafka to end users, and not vice versa. For a company like SuperEats, having all customers and drivers be able to send a stream of data back to the company’s Kafka cluster may actually open up a new set of challenges that would require additional security and maintenance. That was an additional challenge not warranted by our use case.
It’s true that we could have still used WebSockets and just chosen to not implement any client-side push back to Kafka. But that would defeat the main purpose of using WebSockets in the first place.
There are also two useful SSE features absent with WebSockets that tipped the scale in favor of using SSE for Fjord: auto-reconnect, and native infrastructure compatibility.
3.3.2 Auto-reconnect
By default, SSE’s EventSource WebAPI automatically tries to reconnect the client to the server every time the client gets disconnected from the server. Because our use case involved streaming to drivers on mobile devices that may need to switch cell phone towers when driving across town, this seemed like a useful feature.
The auto-reconnect feature also proved useful for auto-scaling purposes. Because, as we’ll explore later, the URL that clients are connected to is actually that of a load balancer, this meant that whenever a server has either crashed or needs to be shut down because of low activity, all of the clients currently receiving data from that server would automatically be reconnected to another existing server.
There was no need for us to configure any additional logic to handle that.
The auto-reconnect feature worked in perfect tandem with the load balancer to persist client-server connections.
3.3.3 Native Infrastructure Compatibility
Lastly, the main advantage of SSE has to do with the fact that it works over the standard HTTP protocol and not a more specialized protocol like WebSockets. This means that SSE works right out of the box with all your infrastructure components like load balancers, proxies, etc.
Configuring your infrastructure to work with WebSockets is of course possible, but it would require using additional libraries and spending more time around configurations.
For all these reasons, we used SSE to stream records from our server to clients.
Next, let’s understand why we decided to specifically build an API proxy for Kafka.
4. What is Kafka?
In this section, we will explore Kafka's role as an event streaming platform, why it often serves as the backbone of an organization’s infrastructure, and finally why it's a great conveyor of real-time data.
4.1 The evolution that led to Kafka
4.1.1 EDA as Messaging Pattern for Microservices
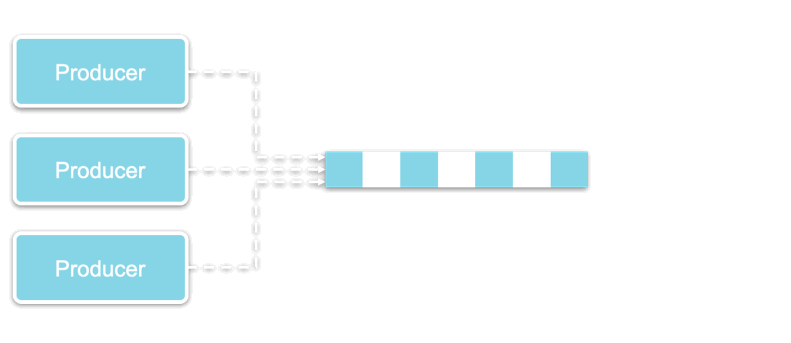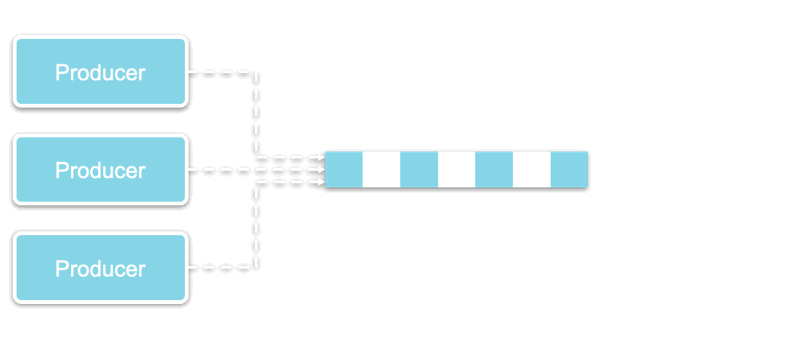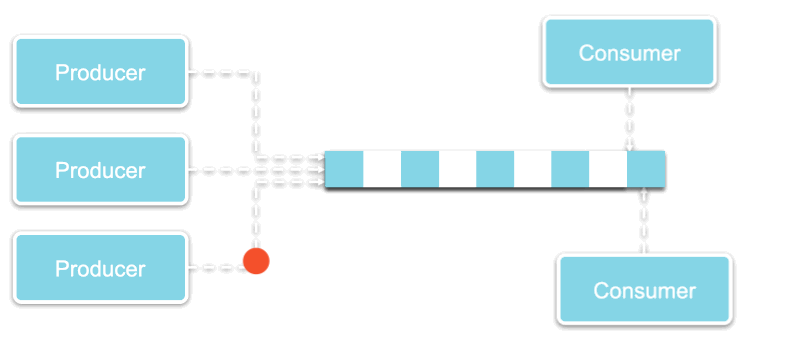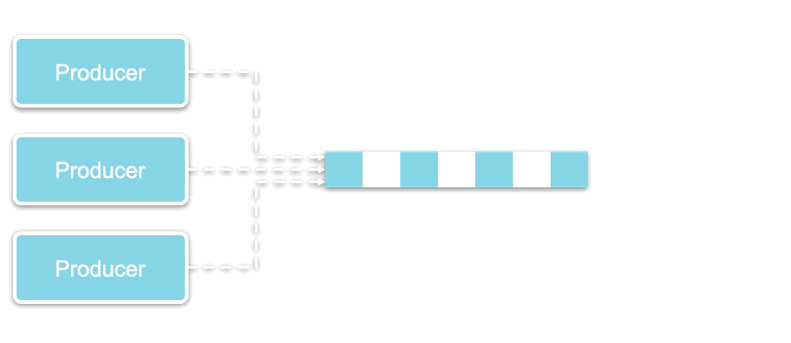
An event driven architecture (EDA) offers a paradigm that decouples the production and consumption of messages (or events) in order to facilitate inter-microservices communication.
By adding a broker in between the microservices that generate events (“producers”) and the microservices that receive events (“consumers”), an EDA allows microservices to communicate with each other without even being aware of each other’s existence.
The three main architectural pieces of EDAs therefore include:
Producers that generate and send events to a broker,
The routing of events through a Broker that acts as a middleware, and
Consumers that have access to any data they need from the broker.
At the core of EDAs are events. An event is any significant occurrence or change in state for a distributed system. An event contains both a payload describing the systemic change or action that occurred, as well as a timestamp of when it occurred.
Producers create and send events to the same broker, and then move on with their own business logic process, completely unaware of what happens to the event afterward.
All consumers that are interested in this particular event can then read it from the broker. For example, the inventory, billings, and delivery services could all react to the same order event. Events are immutable (i.e. they cannot be edited), but they may expire or be deleted.
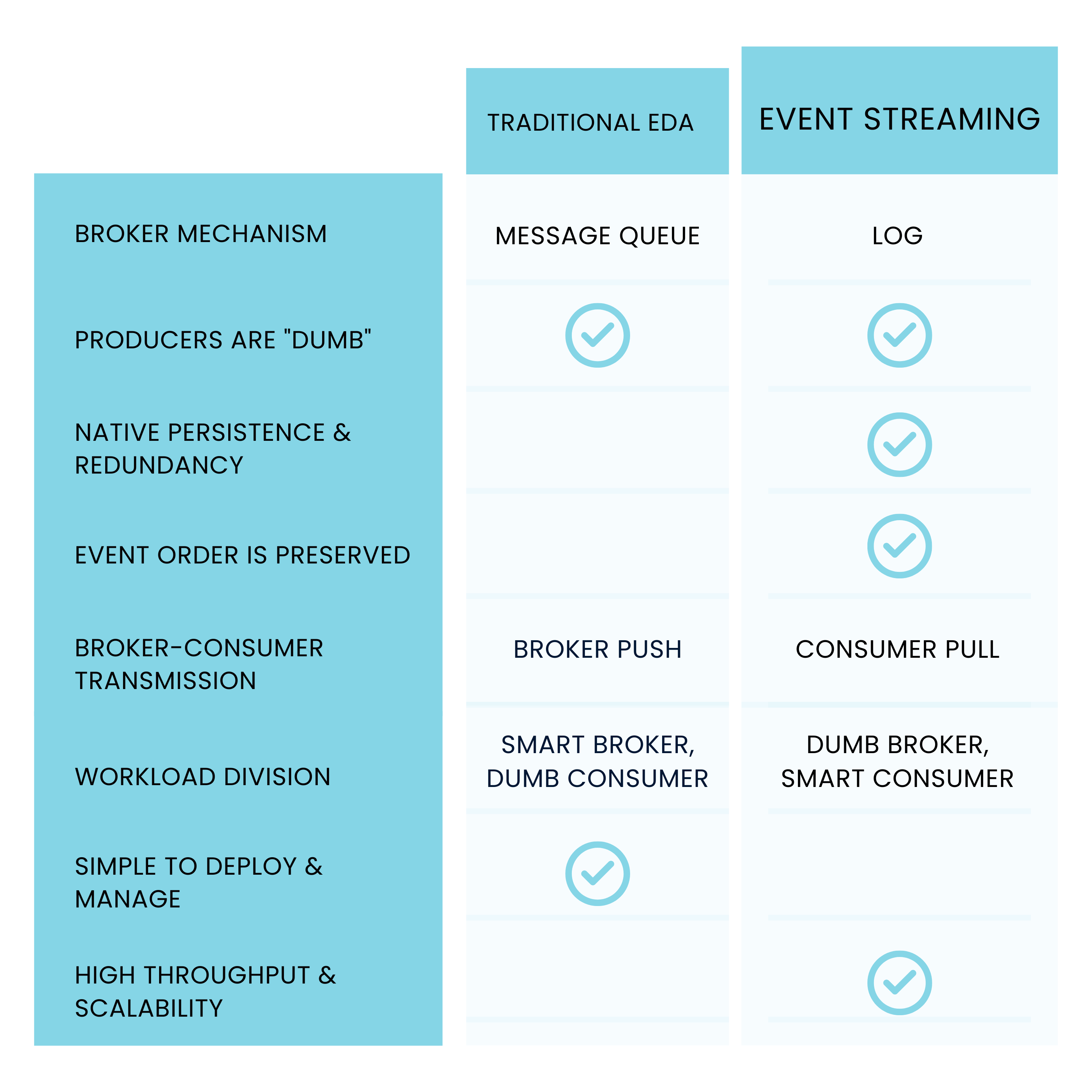
4.1.2 Limitations of Traditional EDAs
Traditional EDAs simplify communication between microservices and are typically based on a message queue model. However, they also present a new set of challenges.
In the traditional EDA model, the broker wears many hats. It has to:
Push events to each appropriate consumer interested in that event,
Keep track of which event was last consumed by each consumer (the “offset” or index), and this for all consumers, and
Delete each event as soon as it is read by the appropriate consumer.
The broker’s workload therefore grows in proportion to the number of consumers and events it must service. More events mean more work and more time is required for the broker to process the events.
4.1.3 Event Streaming
To handle an extremely high flow of events, event streaming platforms were born. They are still considered a subset of EDAs because they have the same three components of producers, consumers, and a middleware broker. However, they are designed to handle a higher velocity of events than traditional EDAs.
The main paradigm shift and key differentiating factor behind event streaming platforms is that the broker actually does less work than it does in the traditional EDA model.
Instead of the broker pushing events to all consumers, each consumer is responsible for pulling each record from the broker. The broker similarly does not have to worry about keeping track of the offset of each consumer, since each consumer handles their own offset themselves.
Finally, the broker does not have to delete events. While traditional EDA technologies use a queue-based structure, where events are deleted after they’re consumed, event streaming platforms use a log-based structure to durably store events.
With event streaming, newly added consumers can not only pick up newly received events, but they can also start to stream records from the very beginning of the log’s creation. This is, of course, only possible because events are not deleted after they are read.
In order to ensure a scalable event streaming platform, where we place more business logic becomes significant. With traditional EDA technologies, the broker holds the bulk of the integration logic. Consumers just receive whatever is sent to them by the broker.
This sets up the “Smart Broker, Dumb Consumer” approach.
In contrast, event streaming platforms opt for the “Dumb Broker, Smart Consumer” approach, placing more integration logic on each consumer instead. This enables a high volume and velocity of events, because there’s a significantly lower relationship between the number of events and consumers on the one hand, and the amount of work the broker needs to do on the other.
In other words, increasing either the pace of events that are entering the system, or the number of consumers reading from the
broker, has a much less noticeable impact on the additional work the broker needs to do.
This finally leads us to our next point, the gold standard in event-streaming platforms: Apache Kafka.
4.2 The rise of Apache Kafka
If data is the lifeblood of an organization, then Apache Kafka is like the organization’s circulatory system. Kafka offers a powerful, scalable, efficient, and redundant infrastructure that allows your distributed services to communicate with each other in real-time.
The technology was created at LinkedIn out of a need to track vast numbers of site events like page views and user actions, as well as to aggregate large quantities of logs from disparate sources within its distributed architecture. It later became an open source project of the Apache Foundation in 2011.
Kafka was designed to be used to manage machine to machine communication. Kafka’s custom binary protocol over TCP is built to take advantage of advanced TCP features (e.g., the ability to multiplex requests and the ability to simultaneously poll any connections).
Kafka is optimized to handle extremely high throughput of messages. Back in 2019, LinkedIn was already processing 7 trillion messages per day on their Kafka clusters. This is probably much higher today.
Today, over 80% of all Fortune 100 companies use Kafka.
4.3 Kafka, Real-time, and SuperEats
A company like SuperEats can use Kafka to set up an infrastructure that can scale as the business grows, without worrying about performance issues down the line.
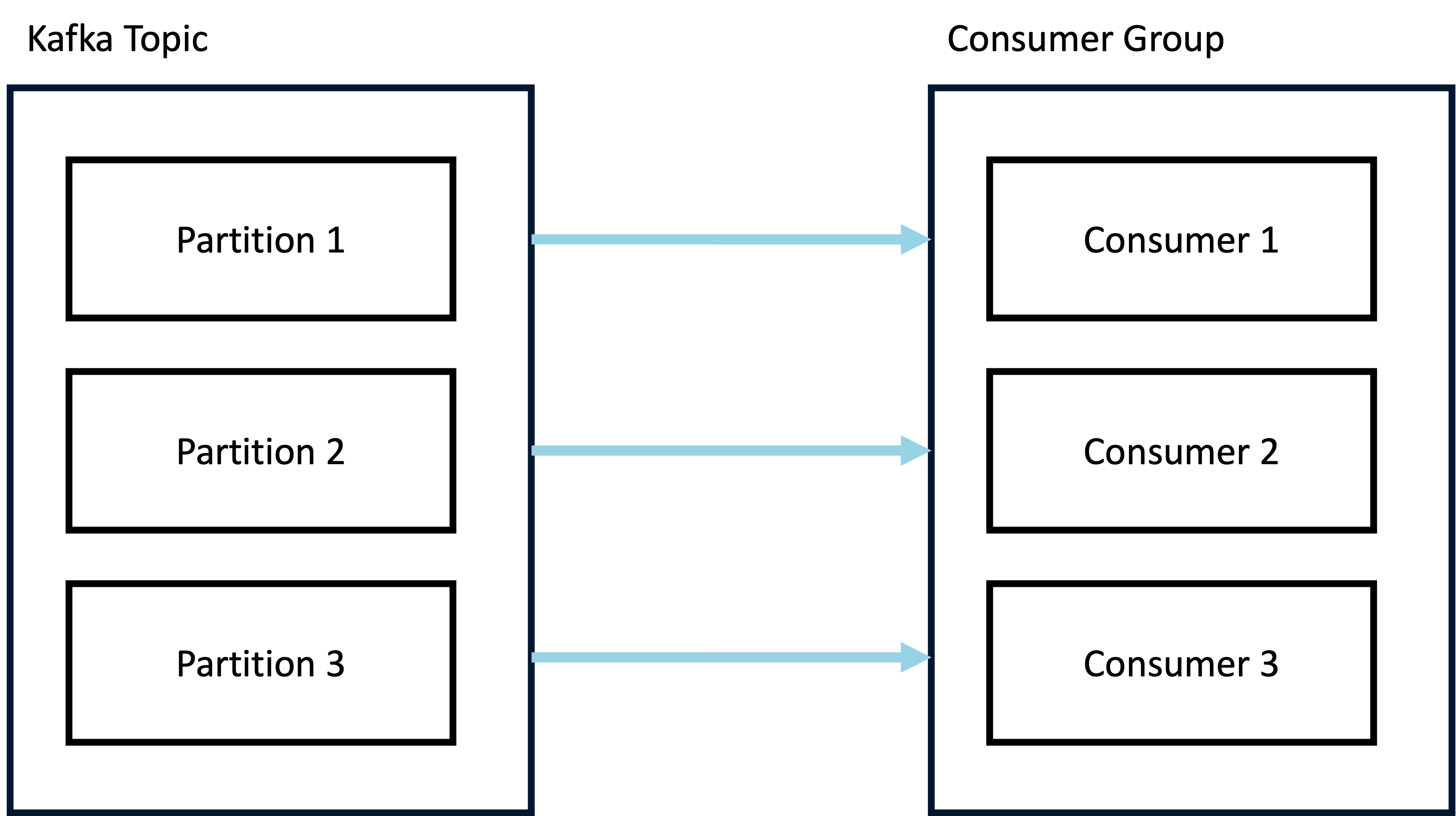
Kafka’s high throughput capacity makes it an ideal candidate to serve real-time events to end users. Kafka is also able to segregate streams of data into any number of topics, which themselves are further divided into multiple partitions. Each partition can have replicas on different brokers, which ensures redundancy in case a broker fails.
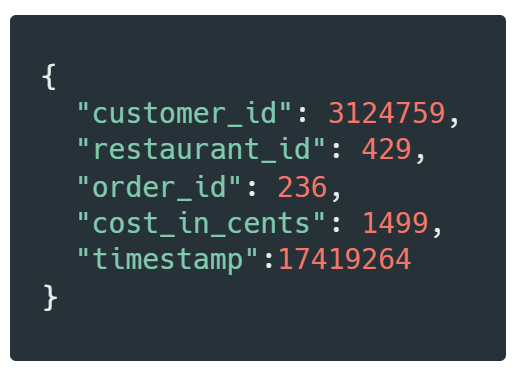
Kafka provides yet another useful component not found in all event streaming platforms--a key. Kafka records have both a payload and a timestamp just like typical EDA events do. However, the payload of a Kafka record is itself comprised of two components: a key and a value. The record value holds the actual business data. But the record key can be a very useful tool to not only further segregate data, but to also ensure in-order delivery.
SuperEats needs a way to segregate data streams by activity type (e.g. incoming order v.s. Driver GPS position), by restaurant, and by customer or driver. For example, SuperEats could have one topic be orders, and another topic be driver GPS information.
Within the order topic, the key of all records should probably be some type of concatenation of three components: the restaurant's, the customer’s, and the order’s unique identifiers. Because Kafka stores all records of the same key on the same partition, this would ensure that all the information related to order 2235407 for Jane4022354 from restaurant 72544986 would be stored on the same partition, and read in-order.
The order topic’s record value would itself contain information regarding the status of the order, the contents of the order, the restaurant's address, the customer's address, etc.
Within the driver GPS topic, the key would probably be the driver’s unique identifier. The value would contain the actual GPS data.
In the next section, we’ll dive deeper into why you need an API proxy if you want to allow clients to stream from a Kafka cluster.
5. Why need an API Proxy for Kafka?
5.1 Protocol Interoperability Issue
Kafka is a robust event streaming platform great for handling high volumes of events flowing between a relatively manageable number of producers and consumers. It uses a proprietary binary protocol designed to facilitate machine to machine communication.
However, internet facing end users use their mobile phones, laptops, tablets and desktops and use the HTTP/S protocol.
As we saw earlier, the choice here is to leverage SSE and receive a continuous stream of data without any additional effort from the end user. There is a clear mismatch between Kafka and the end-user's protocol of consuming streams of data.
5.2 Using an API Proxy as Middleware
An API proxy can be designed to tackle the challenges of moving Kafka data online for public consumption. An API proxy is generally a server that sits between your web application and a backend service. Developers can build web applications using the set of API endpoints without knowing anything about the back-end.
By positioning an API proxy between Kafka and the web, the API proxy can pull data from Kafka over Kafka’s binary protocol, and can push that data to connected devices in real-time via SSE, which is delivered over the HTTP protocol.
5.3 Additional Benefits of an API Proxy
An API Proxy not only makes client-side streaming from Kafka possible, but it also provides some additional benefits.
Letting end users connect directly to Kafka would present some significant security risks. Using a proxy provides an additional layer of security in between end users and your Kafka cluster.
An API proxy allows you to fanout Kafka records to thousands of end users over HTTP, significantly reducing the number of direct connections to your Kafka cluster. Using a proxy also allows you to dynamically scale the servers up and down to respond to external user traffic.
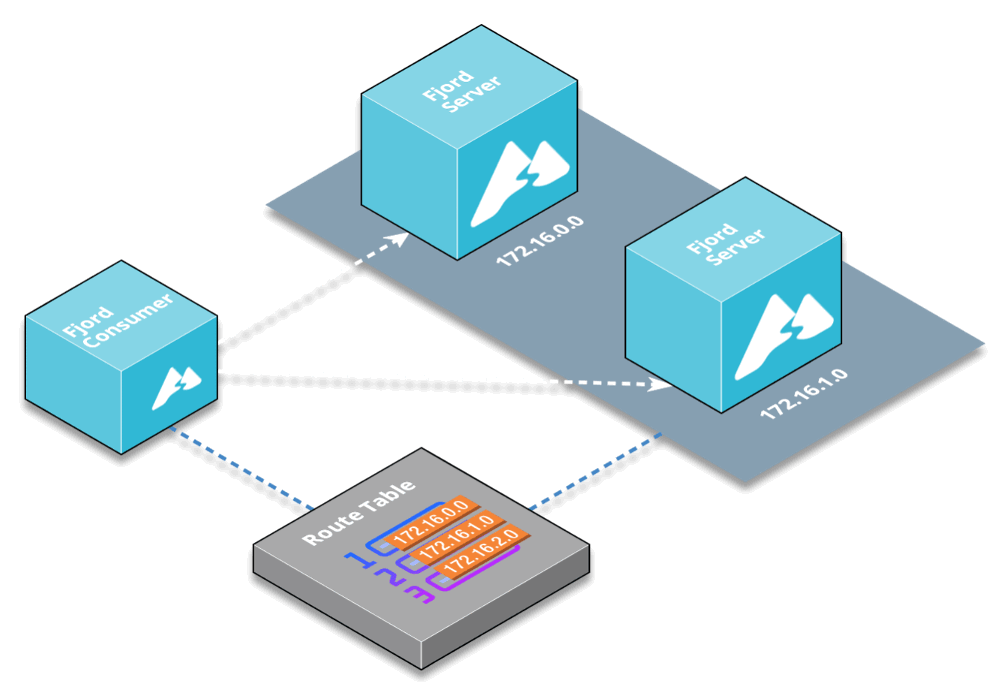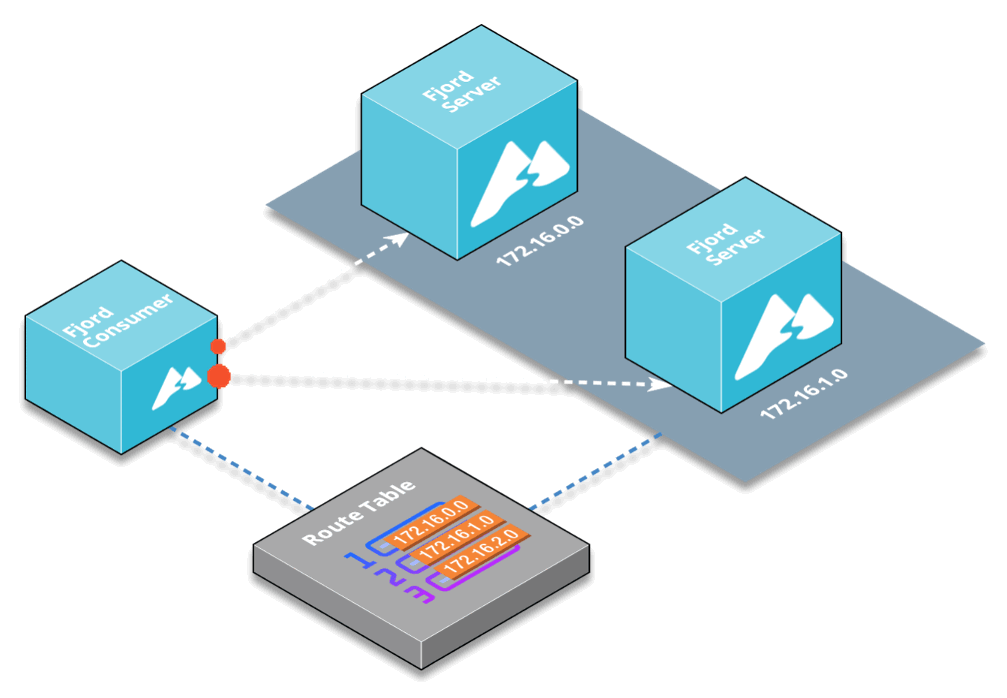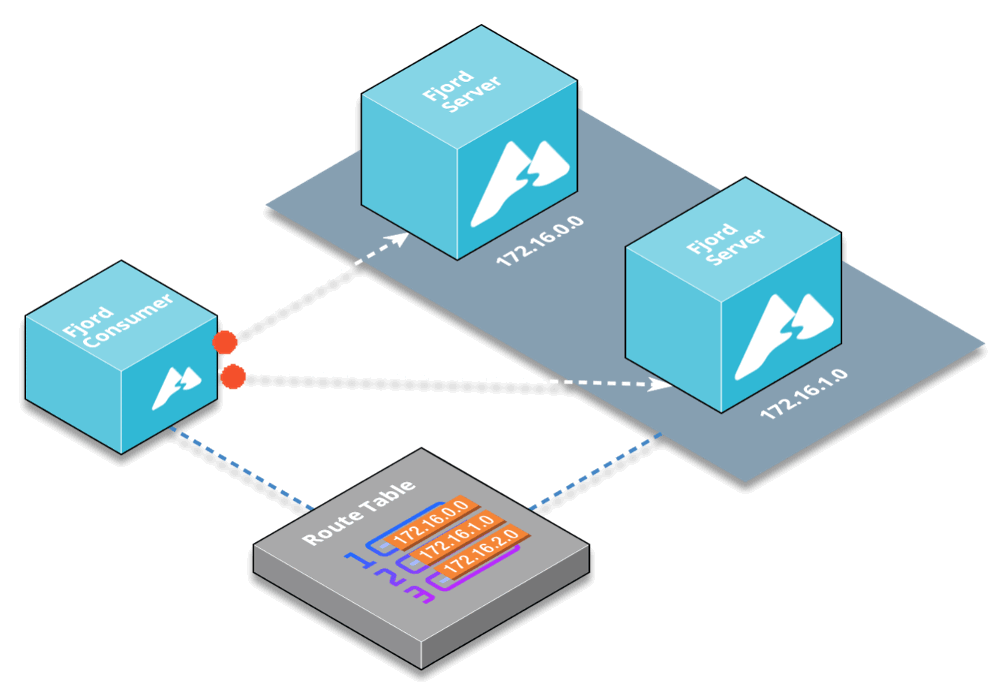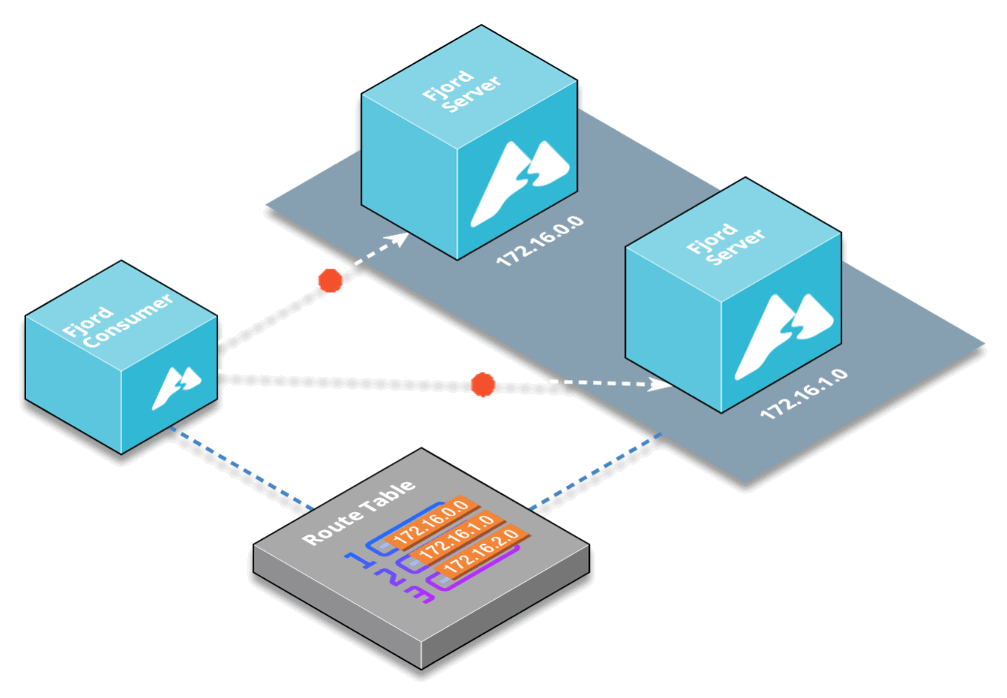
Having an additional layer between Kafka and end users enables more customizations, so you can group various Kafka topics from different Kafka clusters into any number of API end-points with any custom names you want.
This additional messaging layer allows you to offload the resource-intensive task of real-time streaming to an external infrastructure, so you can focus on value creation activities that are central to your business.
What are some existing solutions for this API proxy? Let’s look at that next.
6. Existing Solutions
6.1 Paid Solutions
If SuperEats wanted to use an existing, paid solution, what options would there be?
Ably, PubNub and MigratoryData offer specialized services for Kafka. All of these companies offer feature-rich, highly scalable solutions. The main downside of these services is that you pay a high price for the convenience and ease of use, and you’re locked into their ecosystems.
6.2 DIY Approach
If you wish to go the Do-It-Yourself (DIY) route, you will find many open-source platforms and services to help you accomplish this goal.
The downside to this approach is the time, energy and expertise it requires to connect everything together. Installing and connecting all the different components is a challenge in itself, not to mention deploying and maintaining this infrastructure.
If you want to add scalability into the mix, you have to understand how these components handle load and how to effectively tweak them to meet your use case. This is not always a realistic approach for small to medium sized companies.
6.3 Fjord: the only open source, full-service solution
Fjord positions itself in between the paid services and the DIY approach.
Fjord is a real-time API Proxy for Kafka.
It is open-source, scalable, and simple to deploy to AWS.
Fjord lets you have full and exclusive ownership of the data coming in and out of your Kafka clusters.
We offer a minimal feature set and a simple developer experience so that you can easily add any additional features you want.
As far as we know, Fjord is the only open-source platform that incorporates all the infrastructure pieces you need to deploy an API proxy for Kafka right out of the box.
7. Building Fjord
7.1 Overview of Triangular Pattern
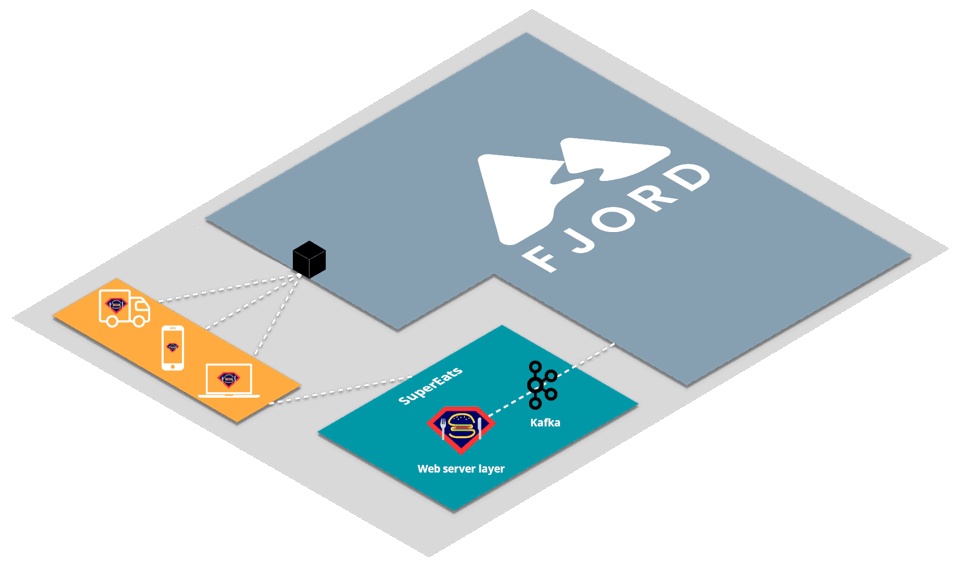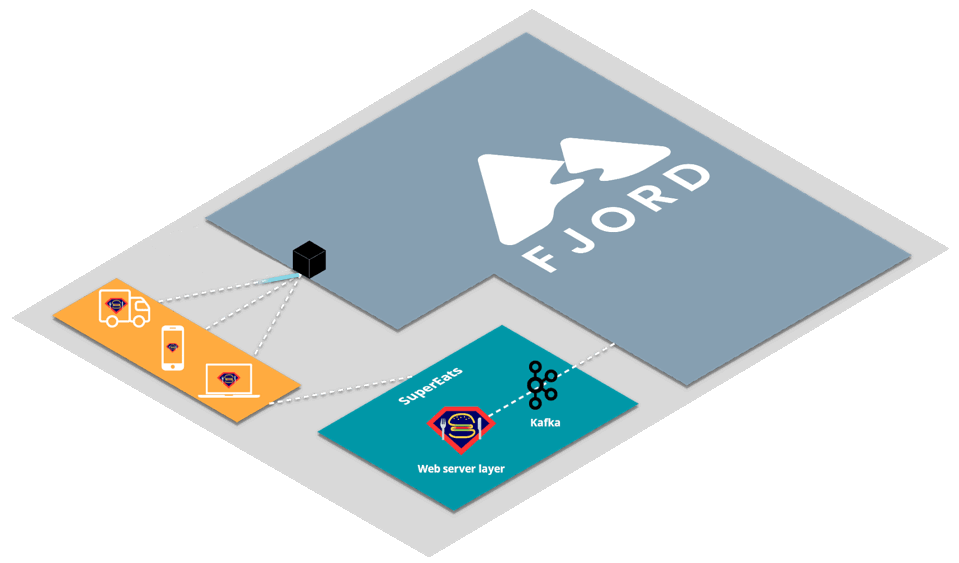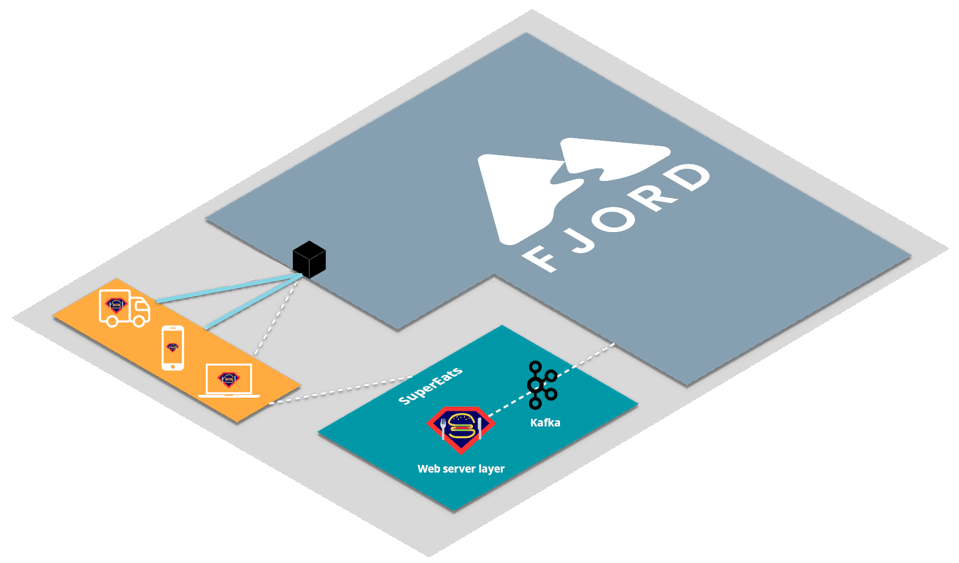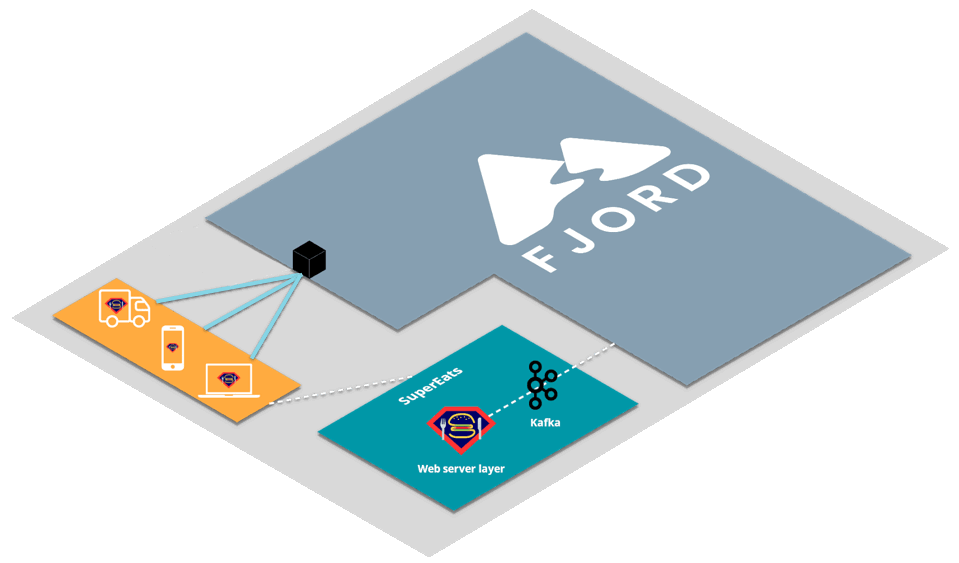
Let’s first look at a high-level view of how an organization like SuperEats would integrate Fjord into their infrastructure.
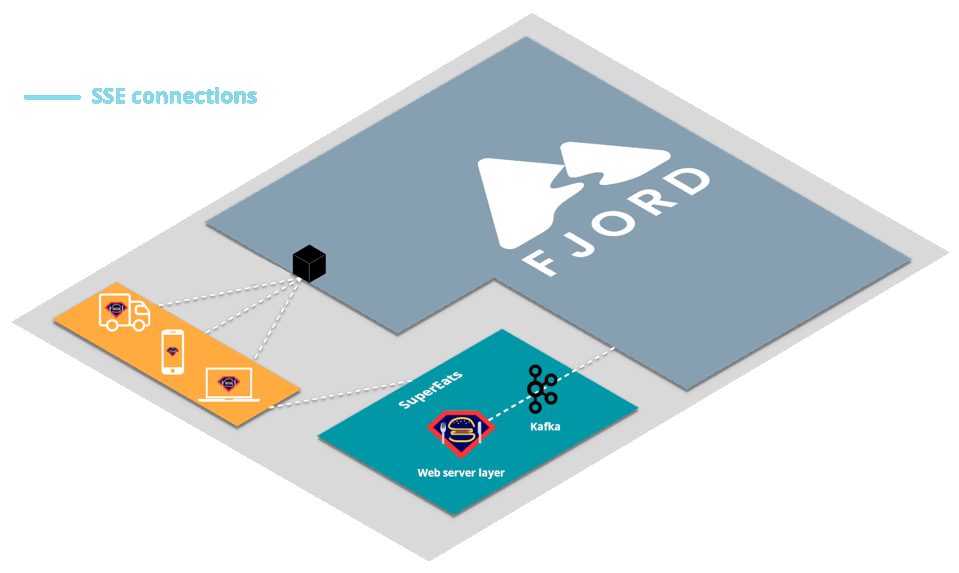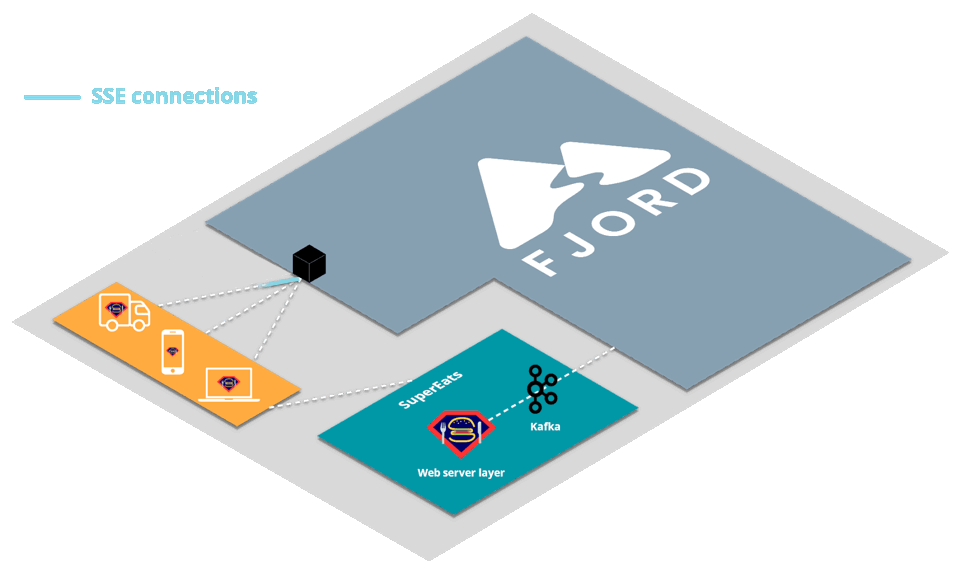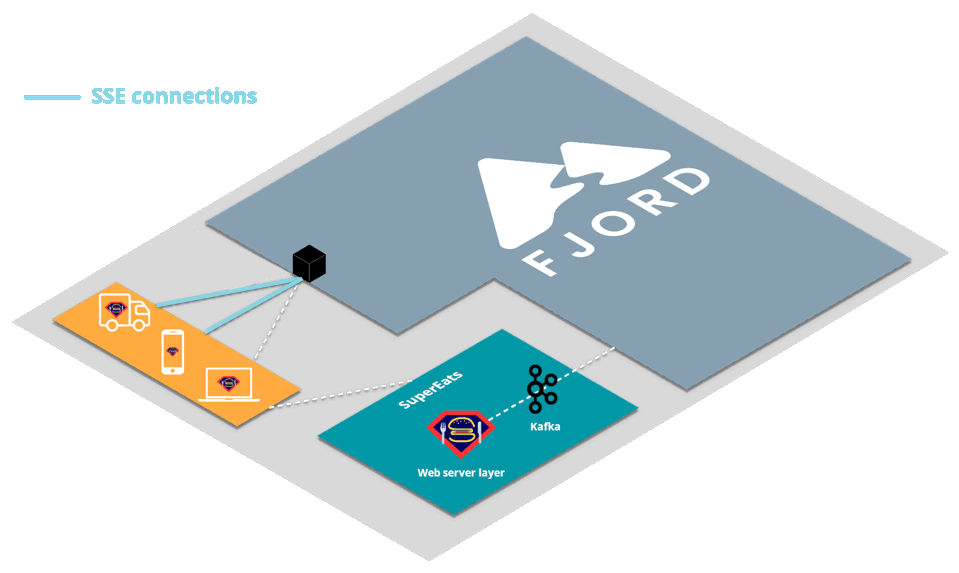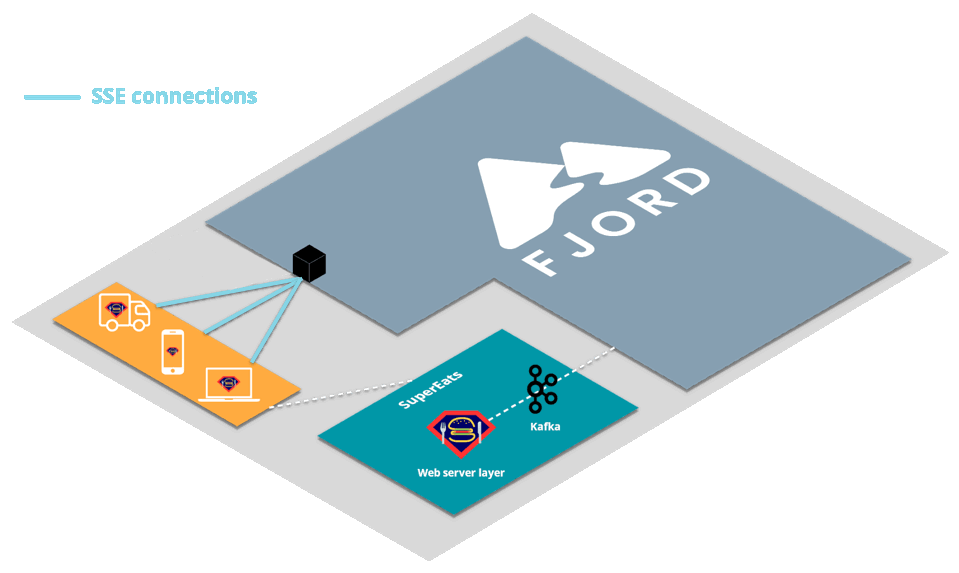
First, SuperEats drivers, customers, and any restaurants working with SuperEats would all connect to the SuperEats web servers on a mobile app or a browser via HTTP/S (e.g., to SuperEats.com).
These servers would deliver, via either a mobile app or a browser, a page that initiates an SSE connection with (i.e. receives push updates from) the Fjord cluster deployed on SuperEats’ AWS account.
Fjord, in turn, would pull records from SuperEats’ Kafka cluster, and deliver them to connected clients who are interested in particular API topics.
It’s important to note that SuperEats drivers and customers are not aware that they are also receiving a data stream from Fjord. From their perspective, all they see is that they’re connected to the SuperEats domain or app.
This allows SuperEats to deliver customized content that has the look and feel of their own website, without having to deal with the additional streaming load on their servers.
This structure is commonly referred to as the triangular pattern.
7.2 Design Goals
We designed Fjord with four main goals in mind:
API Proxy: open Kafka topics to client-side streaming,
Security: enable Fjord business users to restrict access to their Kafka stream through security parameters,
Scalability: create a scalable platform-as-a-service (PaaS) infrastructure, and
Ease of deployment: make deploying Fjord super simple.
In the next section, we’ll walk through the evolution of how we built Fjord to achieve these design goals, and address some of the key decisions we made along the way.
7.3 The Evolution of Fjord
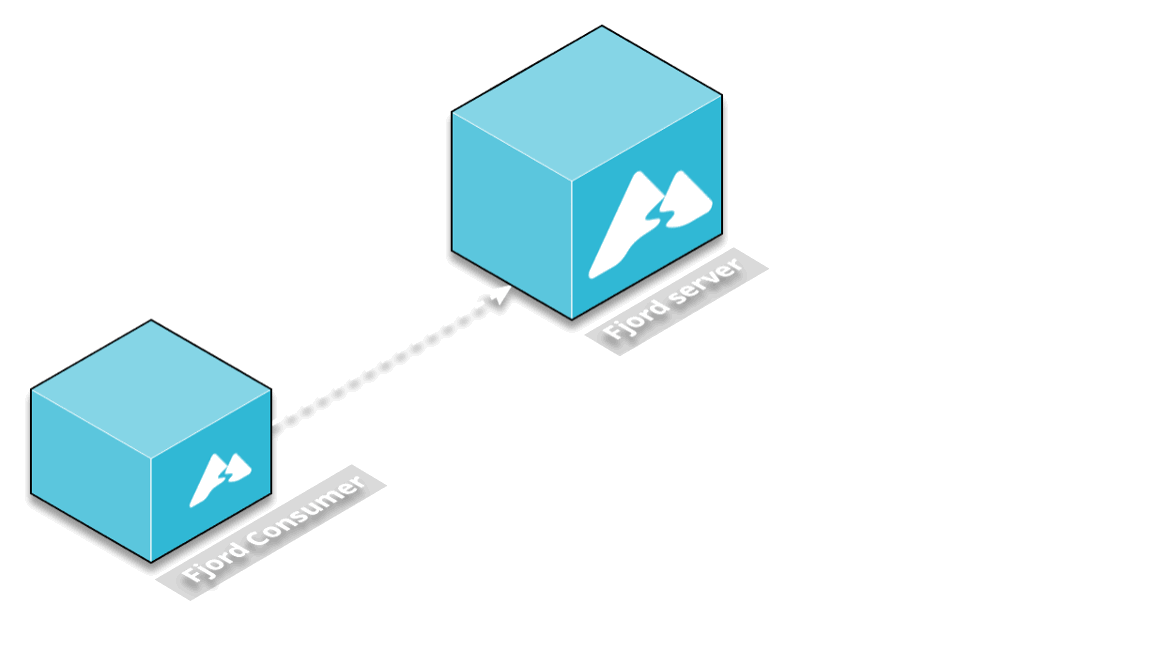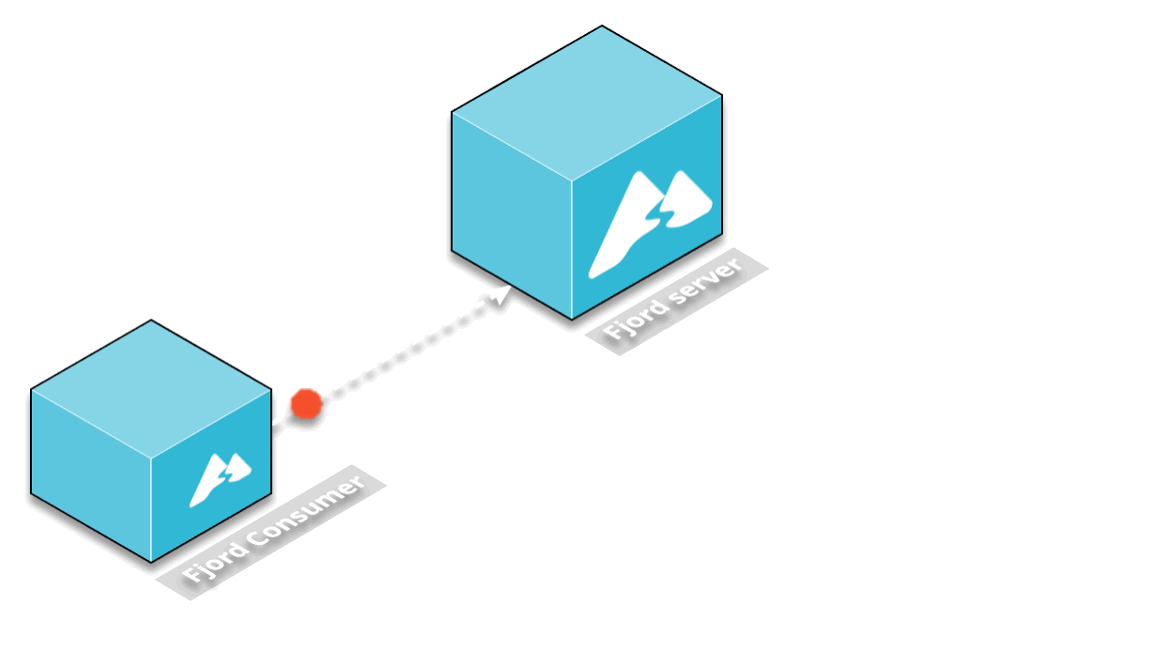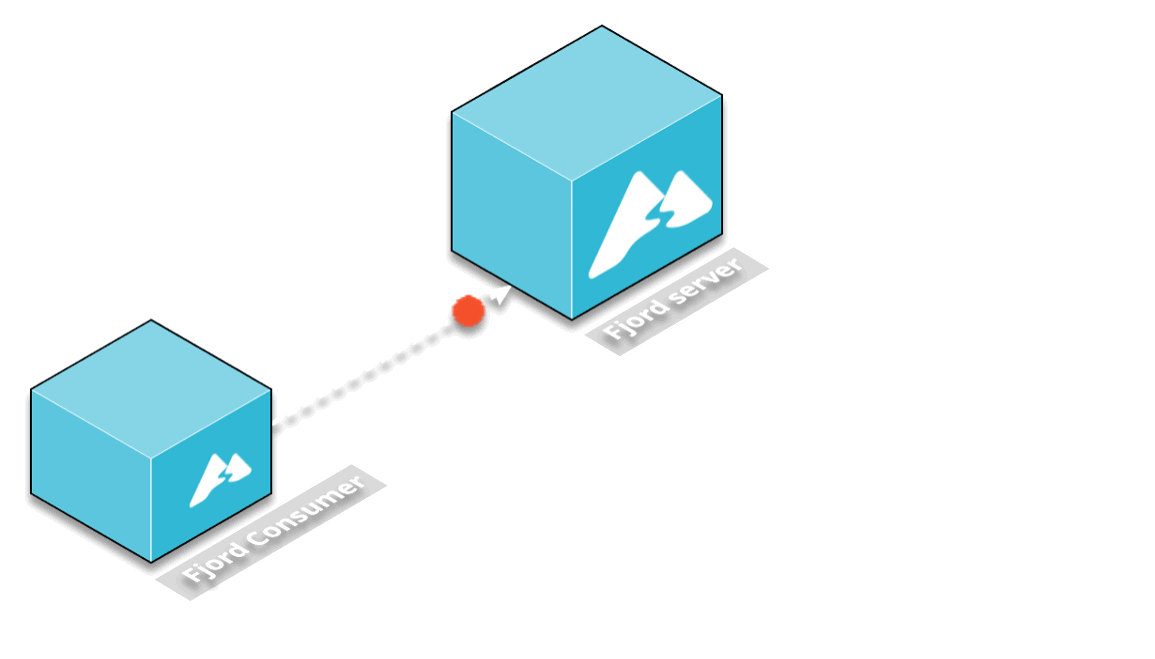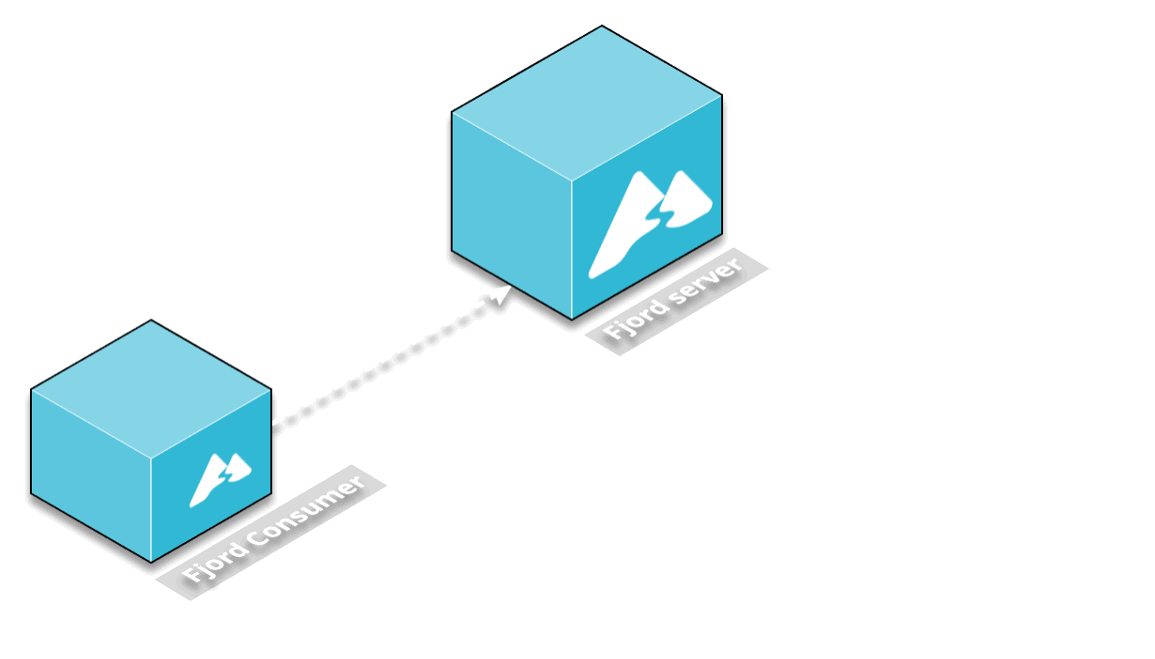
Fjord’s primary components are the server that maintains persistent SSE connections with clients, and the consumer that pulls data from Kafka and moves it to the server.
7.3.1 Setting up a real-time streaming server
Our first step was to build a server that could stream content in real-time to connected clients. To do this, we experimented with SSE and WebSockets, before settling on SSE for our particular use case. After configuring the server, we moved on to extracting data from Kafka.
7.3.2 Learning and Testing Kafka
Our next step was to simulate a business’s Kafka cluster itself, so that we could create a consumer that would be able to pull data from the cluster. We assembled a cluster with three brokers, first locally and then remotely, using a virtual private server (VPS).
Because we planned to work with Node JS, we used a NodeJS client library called KafkaJS. KafkaJS is widely used, well tested, and has an active online and Slack community. This client library also allowed us to start with some default configurations for the consumer and adjust them as needed, and simulate records being produced into the cluster.
7.3.3 Accessing a Secure Kafka Cluster
Kafka is not secure by default, and it can durably store sensitive data. We knew we needed to implement some security measures for the cluster. We enabled a firewall for the VPS and whitelisted the producer and consumer so it could still reach the remote Kafka broker.
Additionally, we implemented SASL authentication for all Kafka clients, meaning producers and consumers would need to provide a username and password to the broker before interacting with the cluster.
One item to note is that we chose to work with SASL-PLAIN, which means our client credentials are not encrypted and could be intercepted as they are sent from the Kafka client to the cluster. In practice, SASL should only be used alongside some form of encryption, like TLS or GSSAPI. We assume that the business using Fjord would have TLS enabled, in which case setting up SASL-SSL is similar to enabling SASL-PLAIN, and relatively simple.
7.3.4 Expanding the Fjord Server with Kafka and JWT
At this point, Fjord consisted of a web server that was able to maintain SSE connections with web clients and a KafkaJS consumer that would push consumed records to our server. We were also able to interact with a secured Kafka cluster. We moved on to securing the front end of Fjord. To do this, we restricted access to the SSE stream using JSON Web Tokens (JWTs), which act as a way to represent claims between two parties over the internet.
Using JWTs, a private key is used by the server to generate valid public keys and then verify that a given public key (i.e. a token) passed back to the server from the client is valid.
Fjord leaves the option of using JWTs up to the business user, via some configuration settings.
With a Fjord consumer able to interact with a secured Kafka cluster and a Fjord server able to securely stream data to SSE clients, the next challenge was making Fjord scalable and deploying it to the cloud.
7.3.5 Dockerizing components & Exploring AWS
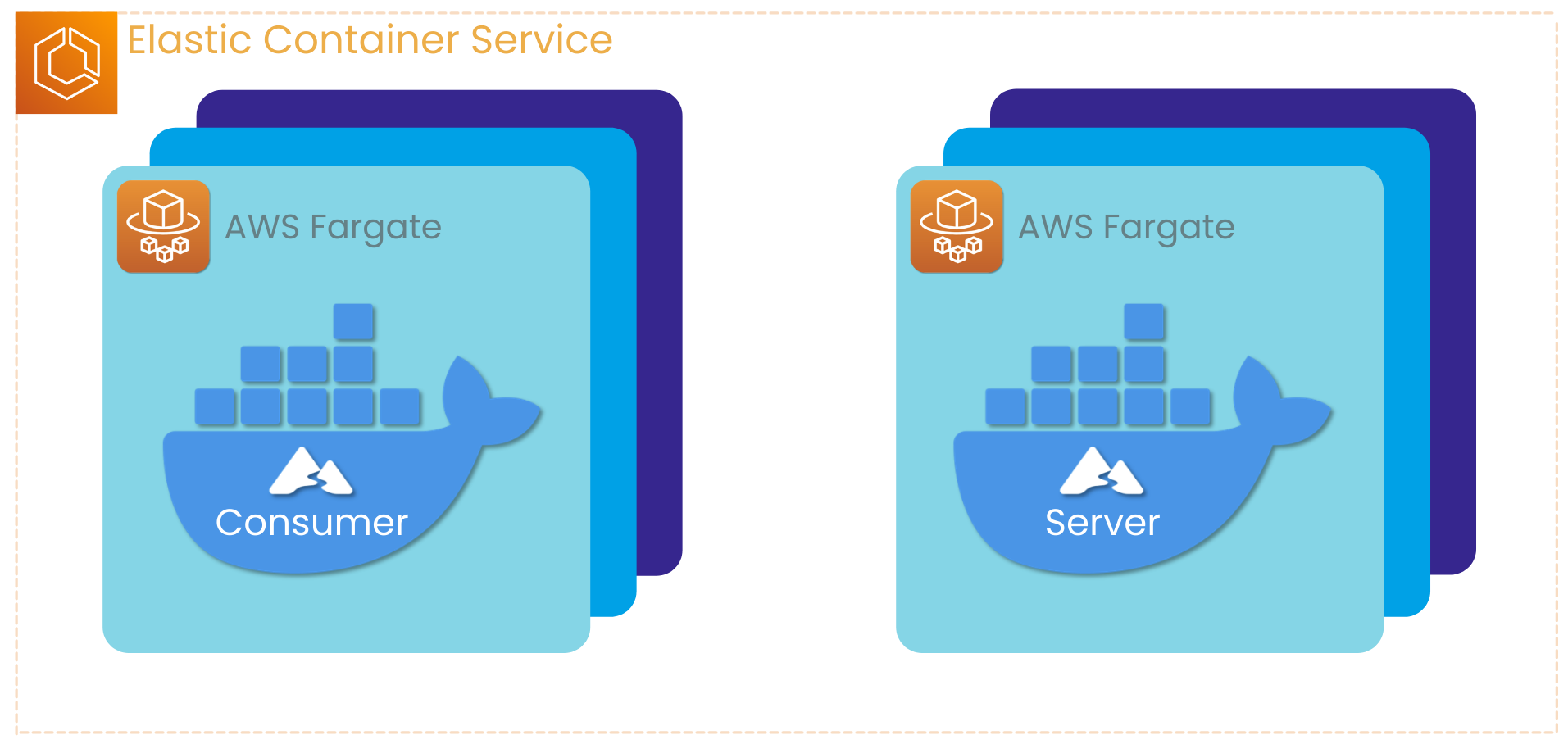
After doing some initial exploration of the AWS Cloud Development Kit (CDK), and the options for deploying infrastructure on AWS, we knew we were probably going to use AWS’s Elastic Container Service (ECS) as it could let us achieve our scalability needs down the line.
In order to use ECS, however, we needed to first containerize both the server and the consumer. For that, we used Docker. This allowed us to run multiple instances of each, with their proper dependencies.
AWS ECS offers two launch types--EC2 and Fargate.
With EC2, you get more control over your deployment, but you need to provision and manage the servers your containers are running on. With ECS and Fargate, AWS manages the containers and the underlying servers they’re run on.
We decided to go with ECS and Fargate, so Fjord business users like SuperEats wouldn’t need to worry about provisioning the underlying servers that the Fjord components are running on.
7.3.6 Decoupling the Consumer and Server
At this point, the consumer needed to be aware of the IP and port on which the server is running, so that it can send POST requests with records to it. This works as long as there’s only one server instance.
But the whole point of using ECS is to be able to scale, and have multiple servers as needed to handle more load. With the current setup, any newly deployed server would not receive records from the consumer.
One approach could be to somehow have the consumer be aware of every newly deployed server, and then make a separate POST request to every server, for every received record from Kafka.
But this approach would put a lot of strain and pressure on the consumer, which is already working hard to keep up with the stream of records coming from Kafka.
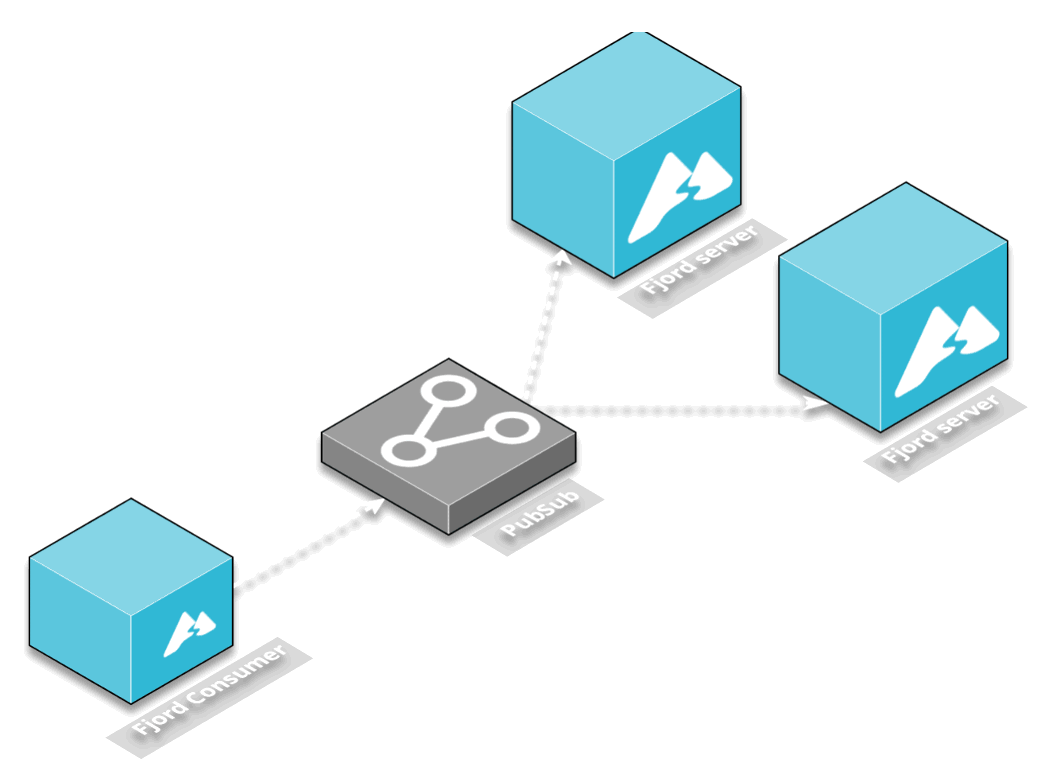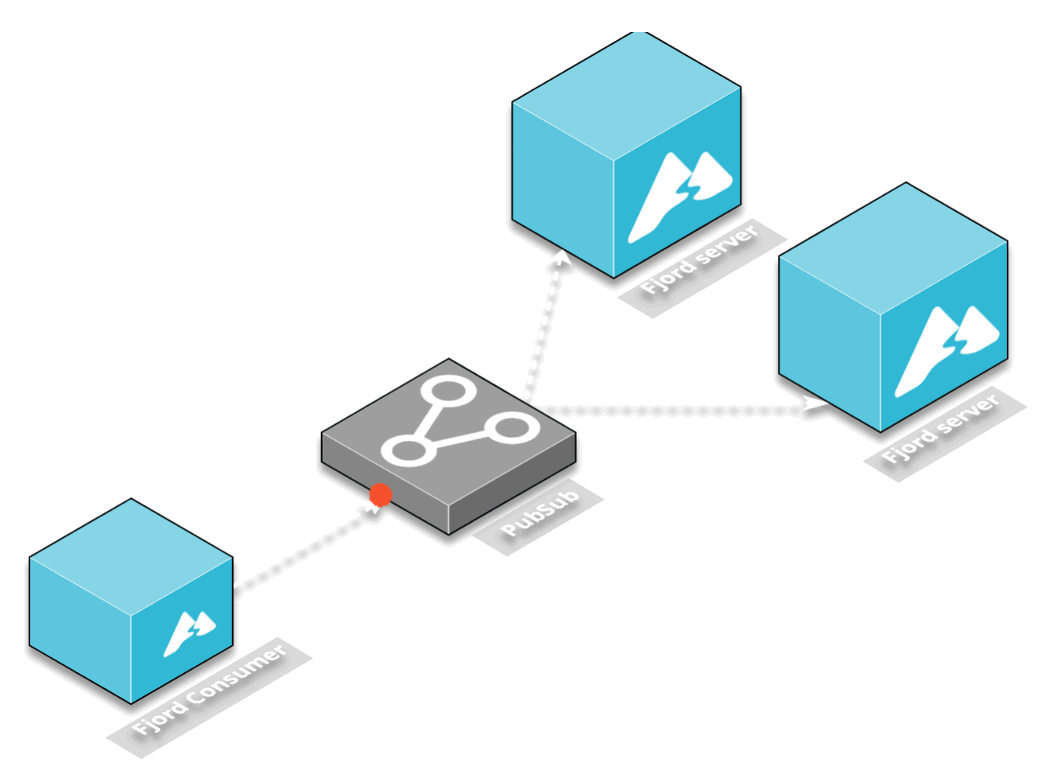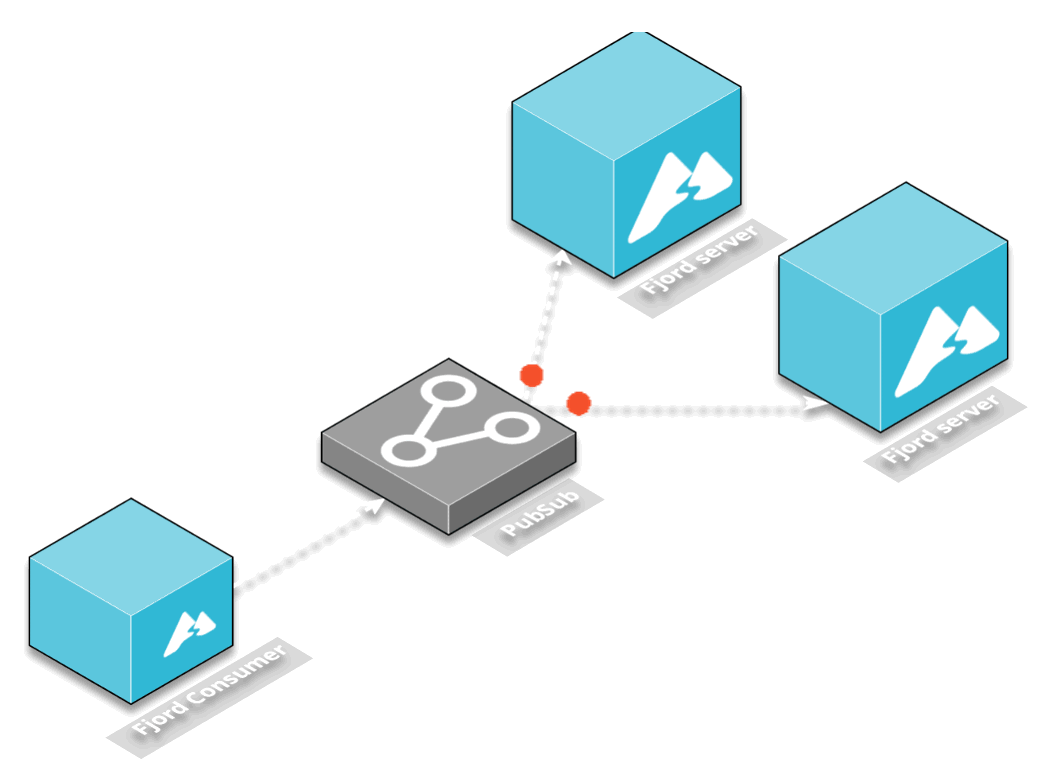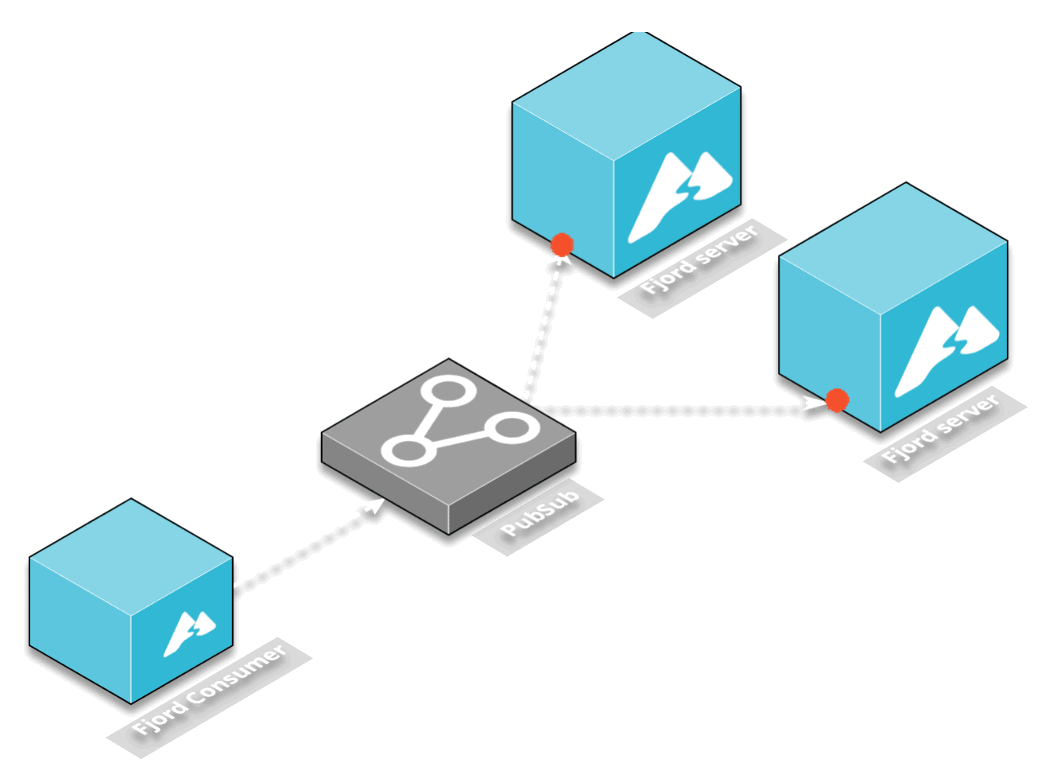
The solution we chose was to decouple the consumer from the server by using a middleware that would provide a publish-subscribe mechanism.
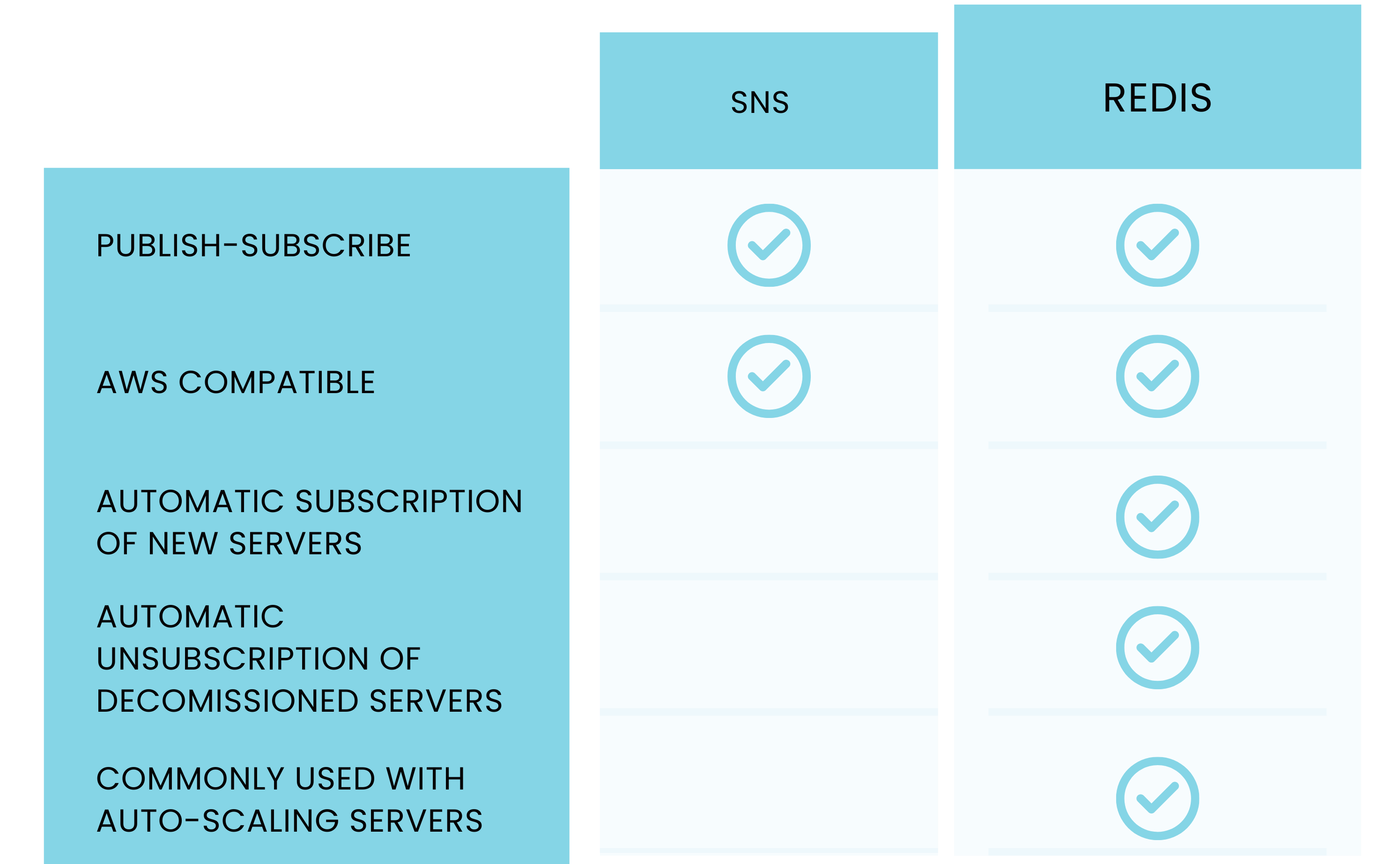
We looked at a few different options for this middleware, including SNS and Redis.
7.3.7 SNS v.s. Redis
One option was to use a publish subscribe model with an AWS messaging service, such as Simple Notification Service (SNS). SNS is a fully managed, publish subscribe messaging service that provides asynchronous message delivery from publishers to subscribers. While SNS is usually used to send data from a microservice to an end user via a text message or an email, it can also be placed between microservices to decouple their communication. SNS can fan out messages to multiple subscribers, which matched with our desire to get the records from one consumer to multiple instances of the server.
However, SNS is a more full-featured service that includes features like message filtering and durable storage of messages, which we did not require. SNS also requires some additional code on our server to handle the initial subscription to an SNS topic as well as logic to handle unsubscribing clients as they close the connection to the server.
Another interesting service was Redis and AWS’s Elasticache for Redis. While Redis is usually used as a caching layer, it also has publish and subscribe functionality. In this architectural pattern, one Redis client can publish to a particular channel on the Redis server, and any number of additional Redis clients can subscribe to that channel.
AWS Elasticache is built to work seamlessly with Redis, which meant that after we configured our consumer to publish to a Redis channel and configured our server to subscribe to the Redis channel, no additional changes needed to be made for Fjord to work in the AWS ecosystem.
After comparing SNS and Redis, we decided AWS Elasticache and Redis would be a perfect fit for Fjord. Redis is extremely fast, lightweight, and required minimal code changes to the consumer and server.
7.3.8 Facilitating Deployments: the AWS CDK and Fjord CLI
Our final design goal was to make Fjord simple to deploy. To facilitate the ECS cluster that the server and consumer live in as well as the Elasticache cluster, more than 40 AWS resources are required, including a virtual private cloud (VPC), security groups, subnets, NAT gateways, an application load balancer, and many others.
It’s possible to manually deploy each resource on the AWS Console, which is the web UI developers can interact with by clicking and specifying configurations. However, this is error-prone and not a repeatable, feasible way to deploy infrastructure on AWS, especially when one of the key design goals of Fjord is to make deployment simple.
AWS CloudFormation allows a developer to model and set up AWS resources by creating a template that describes all AWS resources. Under the hood, AWS takes care of actually deploying and managing the state of all these resources.
One simple way to interact with CloudFormation is to use the AWS Cloud Development Kit (CDK), which allows a developer to write code in a number of their favorite languages that will eventually be translated to a CloudFormation template. We decided to go with the AWS CDK, which makes it as simple as running a few AWS CDK commands to setup, deploy, and tear down all AWS resources.
With the AWS CDK deployment code written, Fjord was now a scalable, secure, PaaS.
But we were not done yet. Using the CDK is still a relatively cumbersome process, with lots of mostly irrelevant outputs to the console.
Our final task was building a Command Line Interface (CLI) on top of the CDK. We designed this CLI to abstract away much of the underlying process, and provide a more streamlined and enjoyable user experience. You can learn more about this in section 8.
7.4 Fjord's Architecture
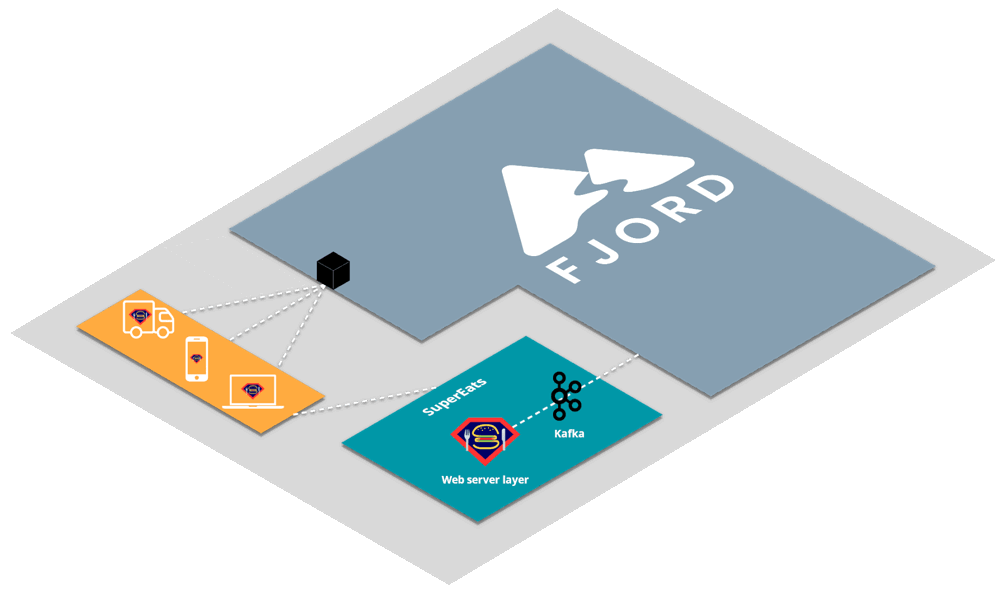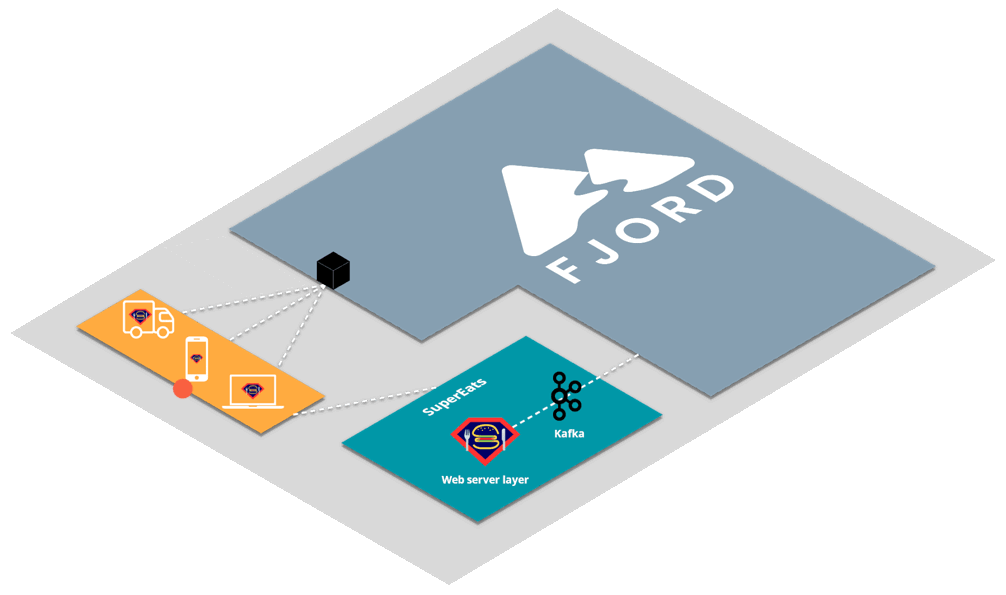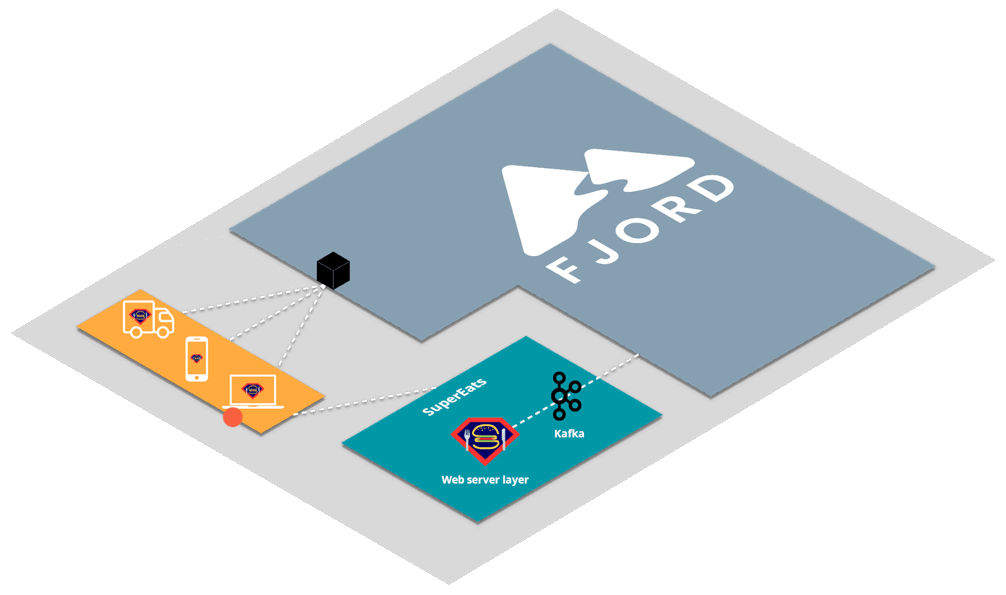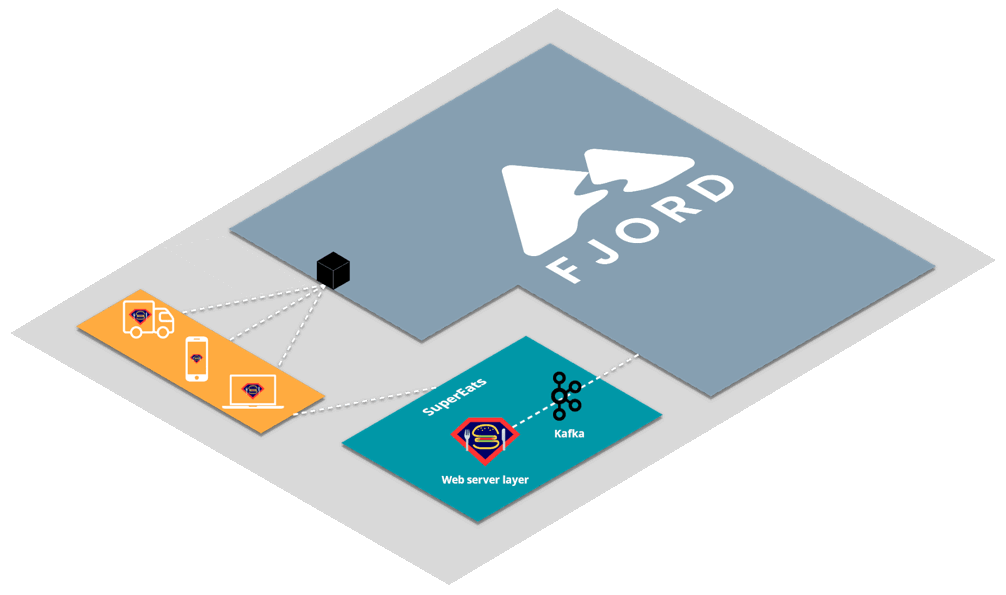
The fully detailed architecture diagram of a deployed Fjord cluster looks like this.
Clients, seen here in the yellow area, connect to Fjord via a load balancer.
The load balancer connects each client to the most available server. These servers are in ECS and managed by Fargate, and automatically scale to accommodate more or less traffic.
On the other end of the process, consumers are receiving data from the business user’s Kafka cluster. This traffic is routed through a NAT Gateway for added security, so that only the responses to requests from the consumers can come into the system.
Finally, sitting in between the servers and the consumers is the Redis pub-sub server. This allows servers to automatically subscribe to all the content being published by all the consumers, and decouples their interaction.
How does all this infrastructure get deployed to AWS? Let's look at that next.
8. Deploying & Using Fjord
There are four steps to using Fjord.
Installing & Using the Fjord Command Line Interface (CLI)
Customizing your infrastructure components
Deploying the Fjord architecture on AWS using the CLI
Integrating your client-side code to work with the Fjord architecture
8.1 The Fjord CLI
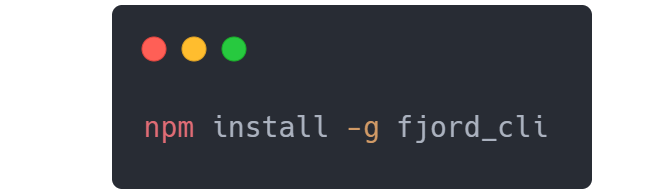
To deploy Fjord, it’s necessary to globally install the fjord_cli npm package, which provides a thin
wrapper over the AWS CDK with a few simple commands.
After doing this, create and navigate into a new directory you wish to use for your new deployment.
8.2 Customizing your infrastructure components
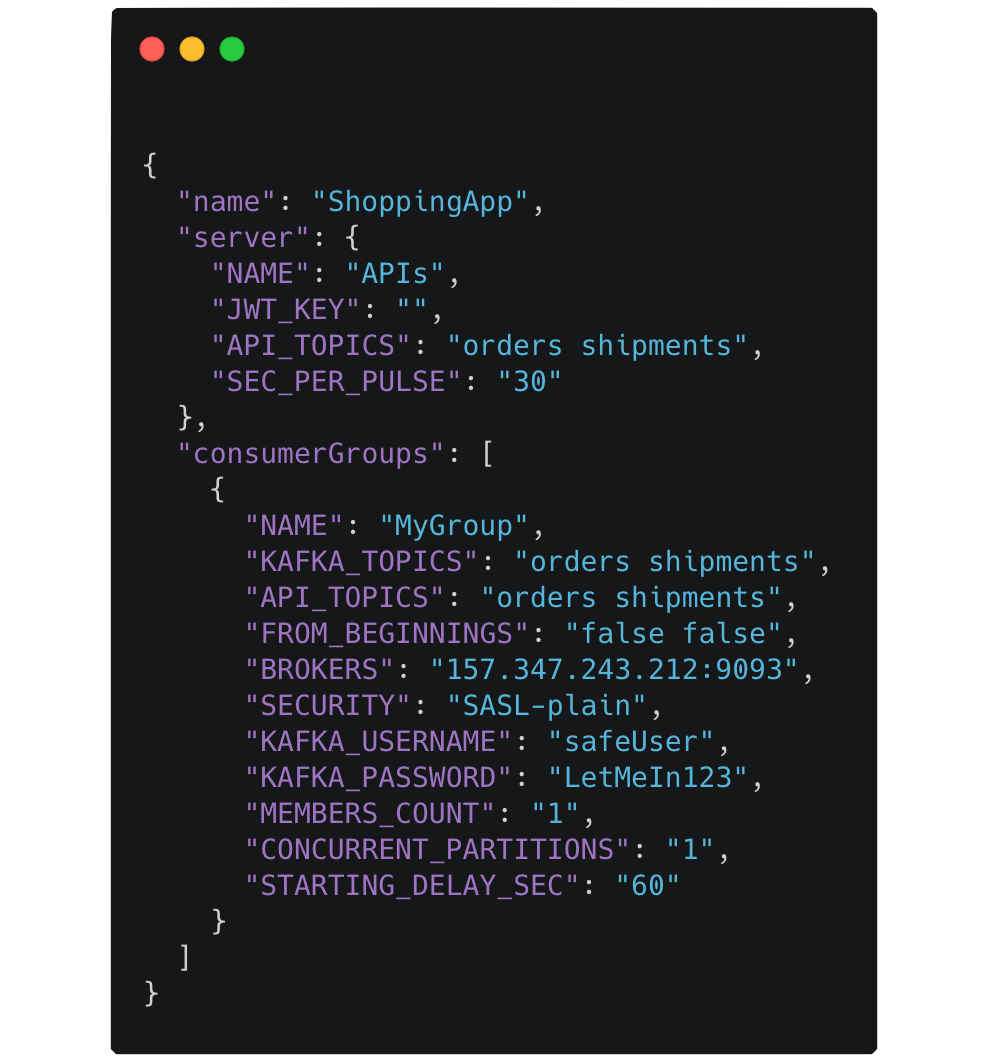
In your directory, use the command fjord setup. This will generate a FjordSettings.json file.
This is where the business user’s configuration details live. This includes the name of your application, an optional JWT private key, the names of the Kafka topics you wish to pull records from, and the names of the topics you want to expose in client side code.
Additionally, all consumer groups should be specified in this file, as an array of objects that each contain the configurations like the name of the Kafka consumer group to which it belongs, and any details necessary to access the Kafka cluster (e.g. Broker IP addresses, security information, etc).
8.3 Deploying Fjord to AWS
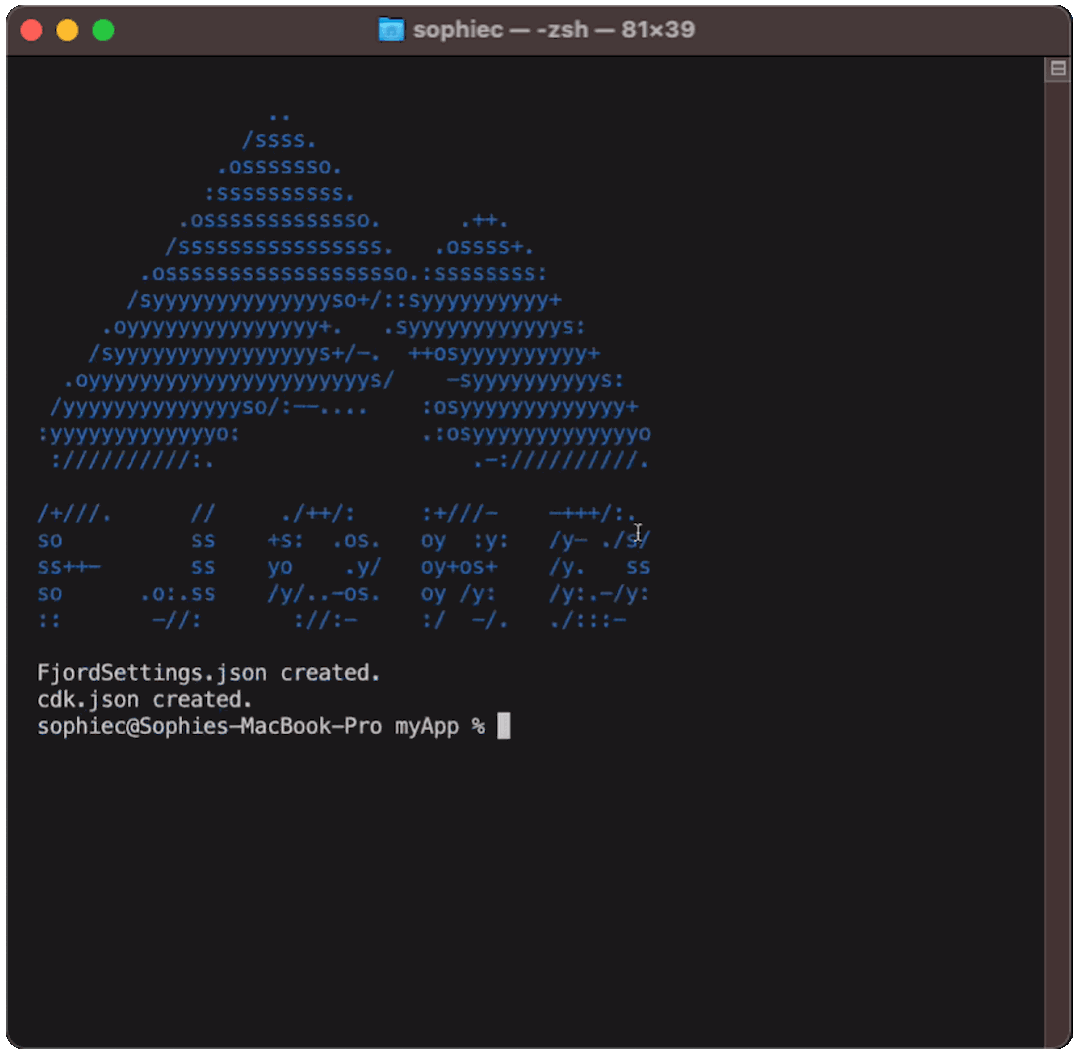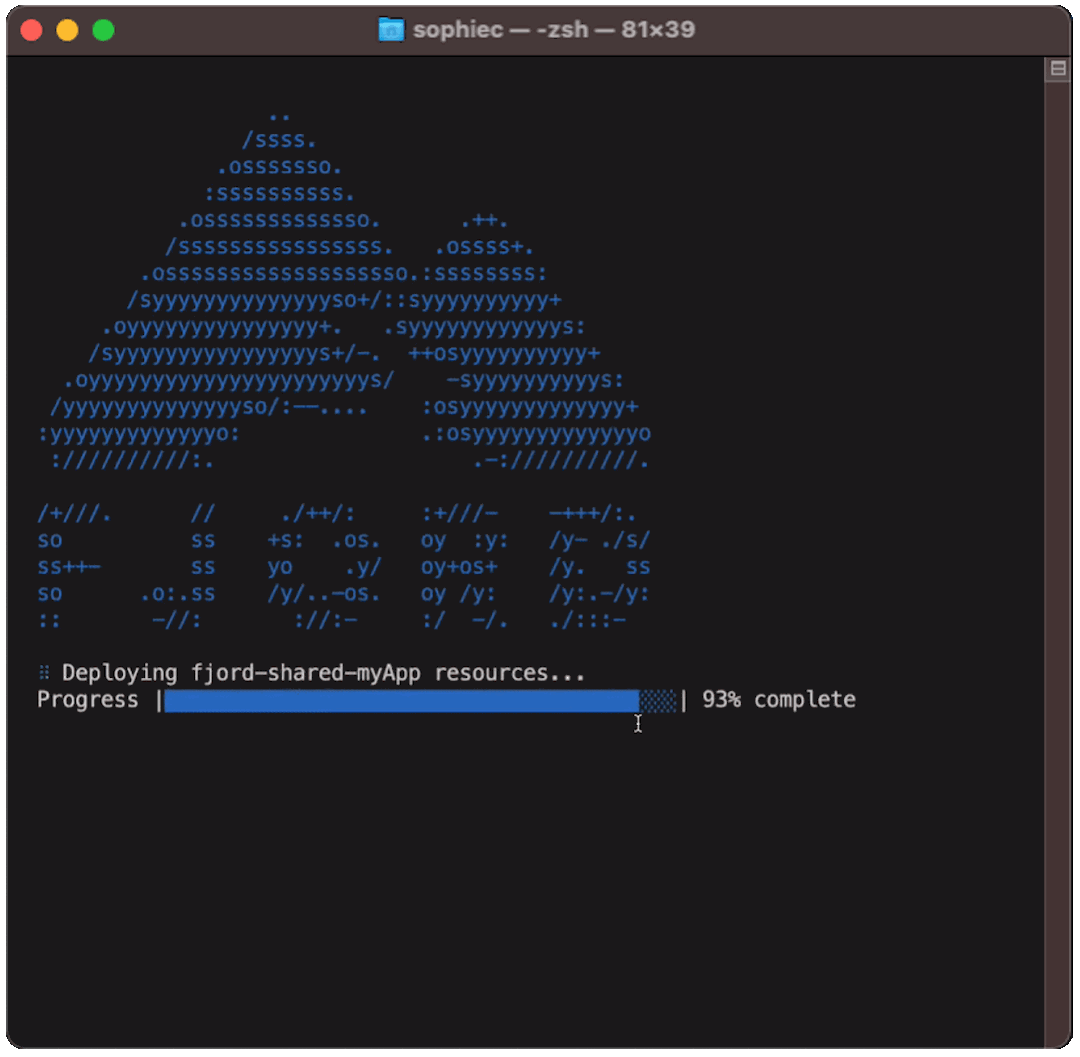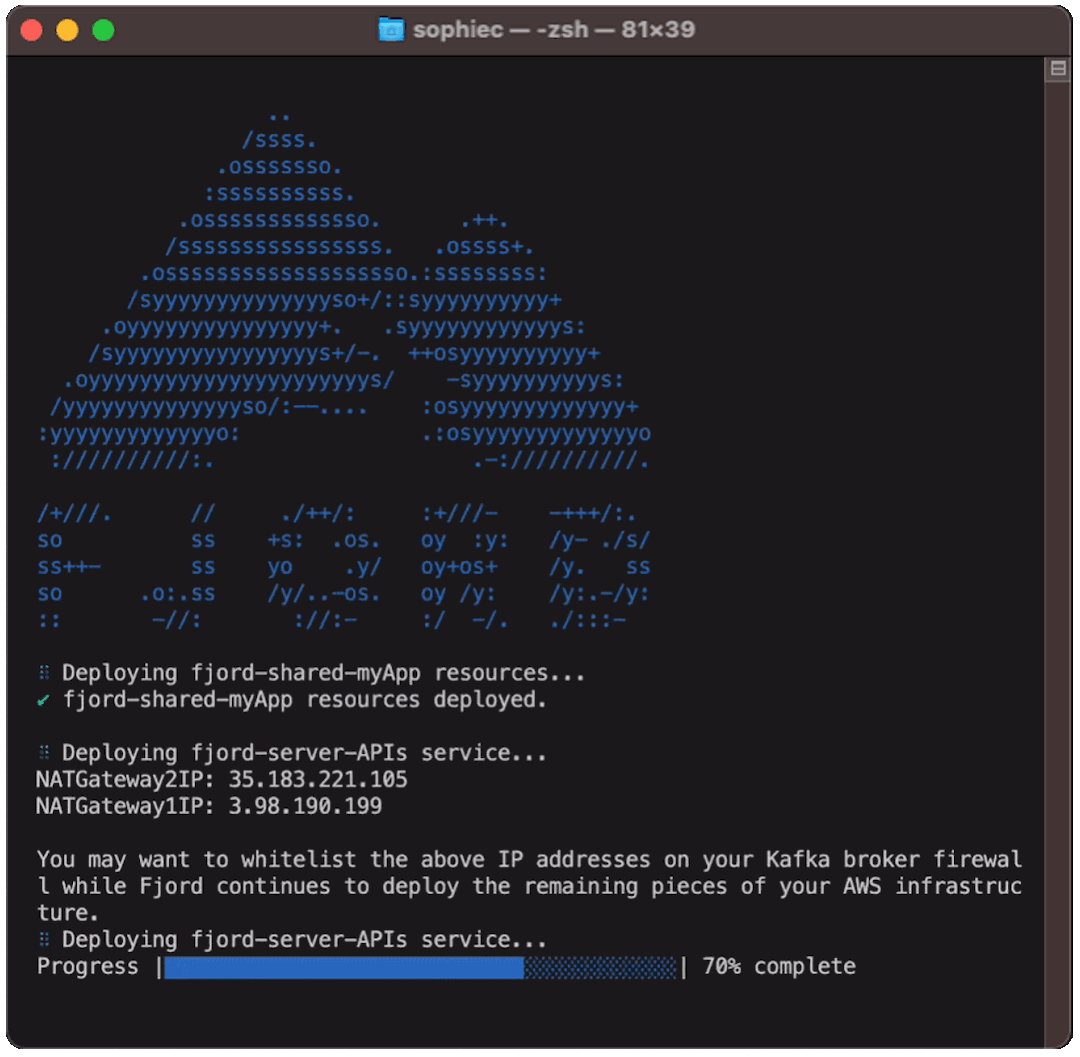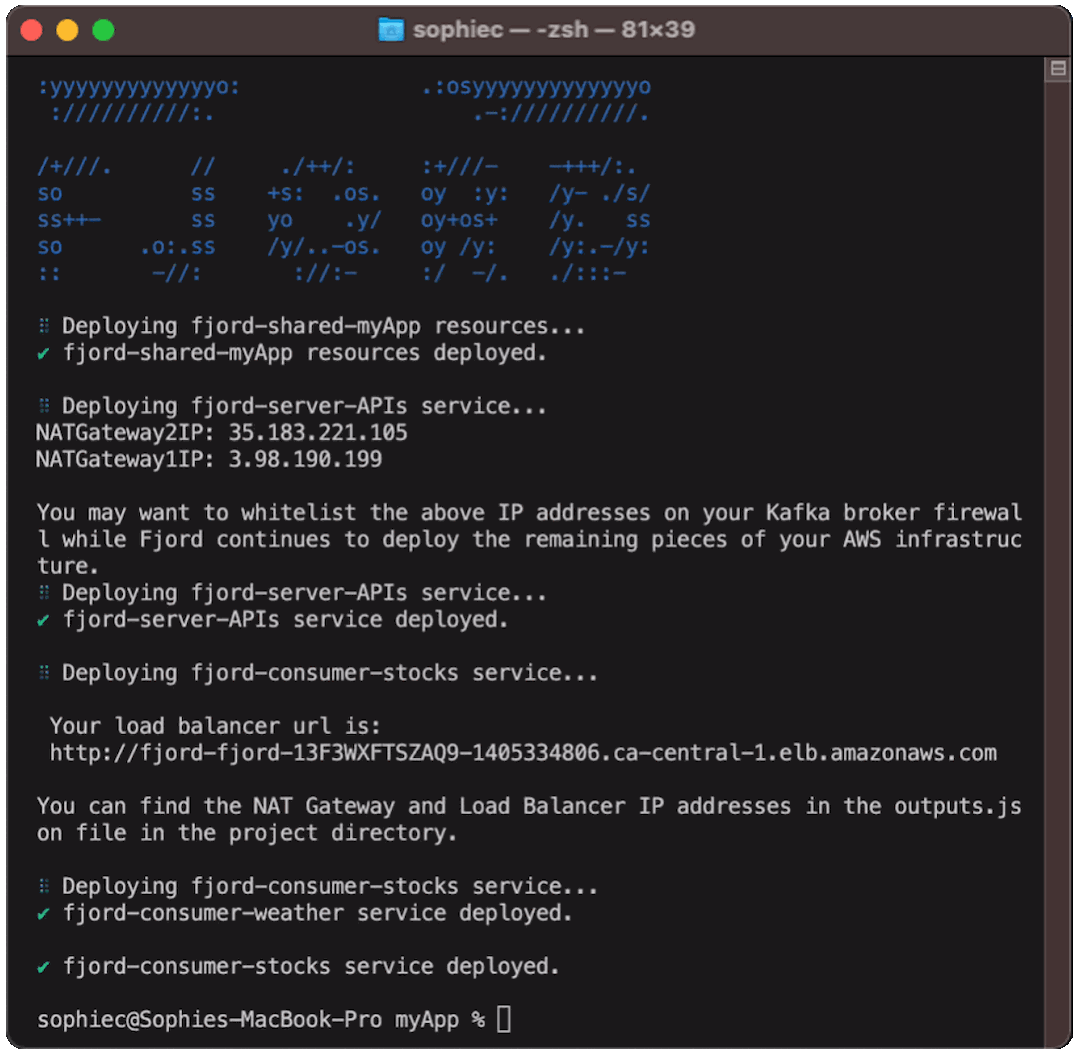
After you’ve edited the settings file, run fjord deploy. This will provision and create more than 40 AWS resources needed for Fjord’s infrastructure and provide you with IP addresses for your NAT Gateways and the Load Balancer URL.
If the business user has a firewall for the Kafka cluster, they’ll need to whitelist the IP address of the NAT gateways to ensure the Fjord Consumer is able to access the Kafka cluster.
8.4 Client-side Integration
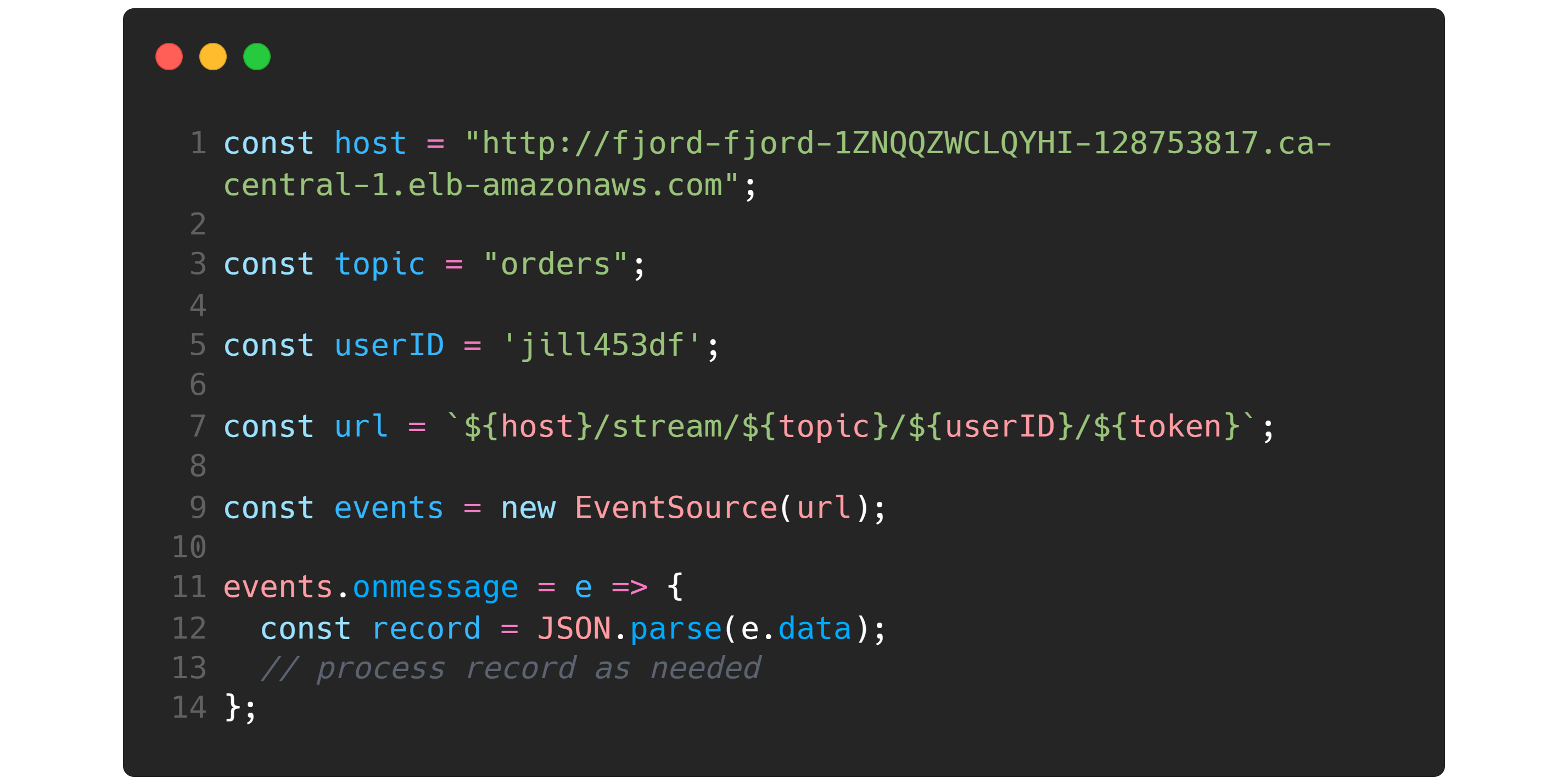
To interact with Kafka from an HTML page or a mobile application, the business user will need to integrate their client-side code with Fjord. To do this, just a handful of lines of code will need to be added to their existing client-side code.
The load balancer's URL that was output when Fjord was deployed needs to be used to establish a SSE connection using the EventSource API for browsers or a similar web API for Android or iOS mobile apps. A topic and userId also need to be specified, along with an optional JWT token, if the business user has configured their Fjord infrastructure to use JWTs.
Finally, the front end developer can write the body of a callback function passed to the onmessage method, which will be executed each time a new record is received by Fjord.
Each incoming record should be parsed from a text to a simple JavaScript object, which can then be incorporated into the page however the front end developer wants--whether as an additional row in a table, a data point on a graph, etc.
9. Technical Challenges
9.1 Auto-scaling and Load Balancing
9.1.1 What should auto-scale?
With Fjord deployed on ECS with Fargate, Fjord was ready-to-scale. Deciding which aspects should be automatically scaled, and which should be manually scaled, was the first challenge.
Kafka’s smart consumer groups are Kafka’s native mechanism for implementing horizontal scaling. Kafka allows multiple members in the same consumer group to split the workload of reading from the same topic, each member reading from a different partition. Because the business user has the ability to specify any number of members within each consumer group when deploying Fjord, we thought this manual mechanism would allow Fjord to take advantage of Kafka’s native scaling capabilities. We decided that the consumer tasks should therefore not be auto-scaled, as we did not want ECS alarms to conflict with Kafka.
However, we decided to focus our auto-scaling efforts on the server. The servers could be scaled up and down depending on several different metrics, or what AWS calls alarms.
9.1.2 Auto-scaling alarms
To set up scaling for the server, it was necessary to configure CloudWatch alarms that would trigger when a server instance met a certain threshold of a given metric. AWS Auto-Scaling Groups could then be used to spin up (or down) an instance of the server. Metrics like CPU, RAM, and number of client connections could all be used to set scaling policies.
Fjord employs autoscaling policies based on the memory and CPU usage of each instance of the server. Whichever reaches a pre-established threshold of percentage usage will trigger a new instance of the server to be spun up.
Using auto-scaling policies based on memory and CPU allows the server to scale horizontally in response to either the number of front-end connections with clients that the server is handling, or based on the number of records the server is receiving from the Kafka consumers, since distributing each record to all clients requires more CPU usage.
9.1.3 Load Balancer Algorithm
By default, the AWS Application Load Balancer (ALB) uses a round robin algorithm to distribute traffic across all the available servers. This is not an optimal algorithm for our use case, because it could result in an uneven distribution of clients on the servers, as it doesn’t take into account the fact that some client connections may have closed.
With a round robin algorithm, if one server has only 10 clients and another has 8000, they would still be
receiving the same number of new requests.
To better distribute traffic by taking into account each server’s current workload, we reconfigured the ALB to use a Least Outstanding Requests (LOR) algorithm.
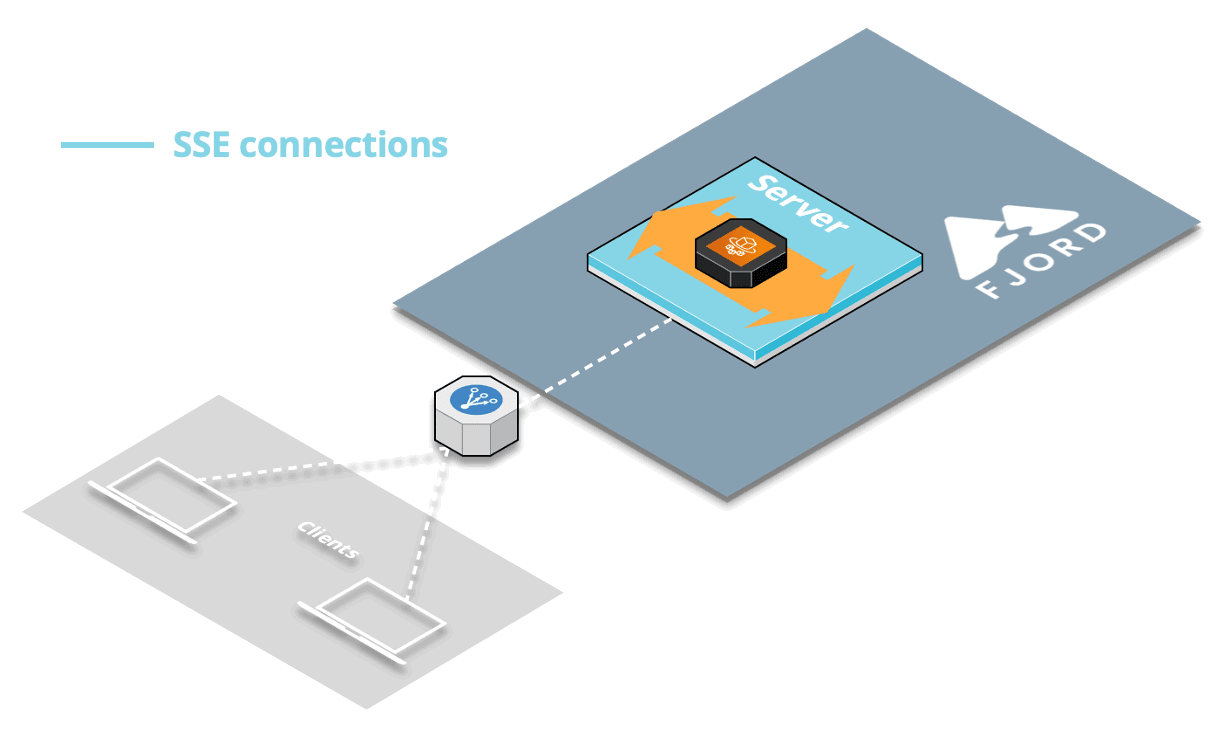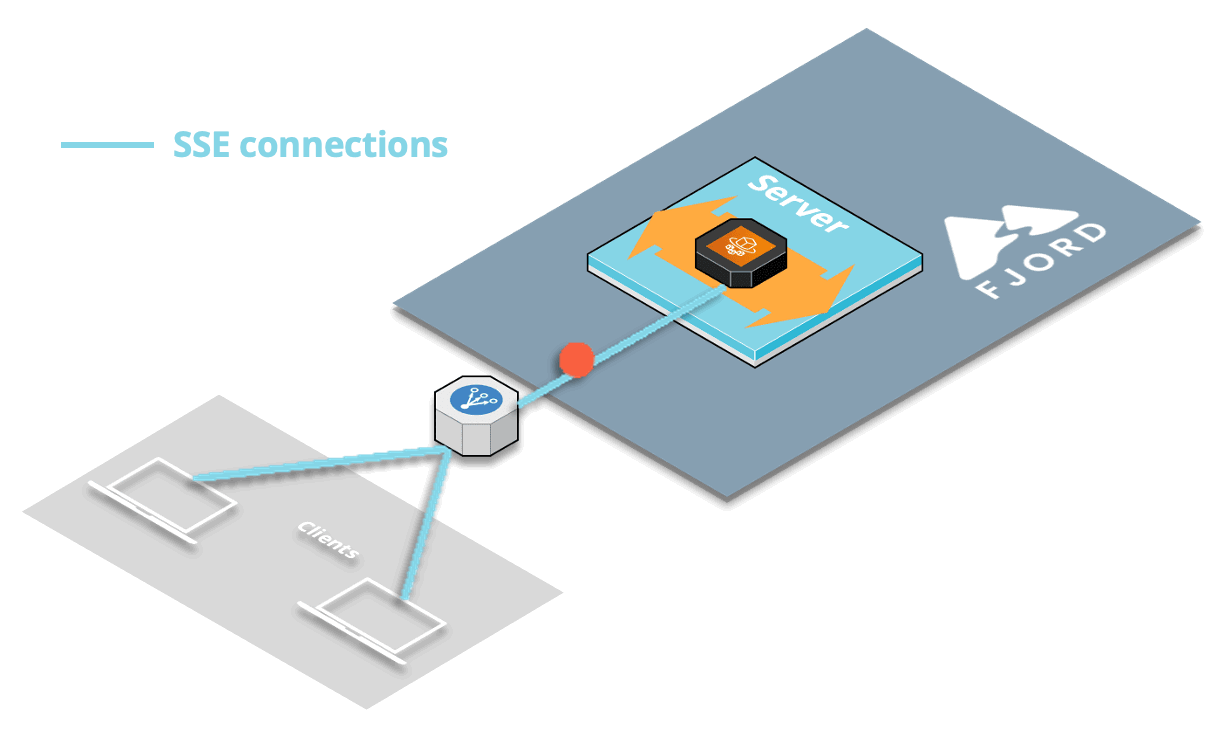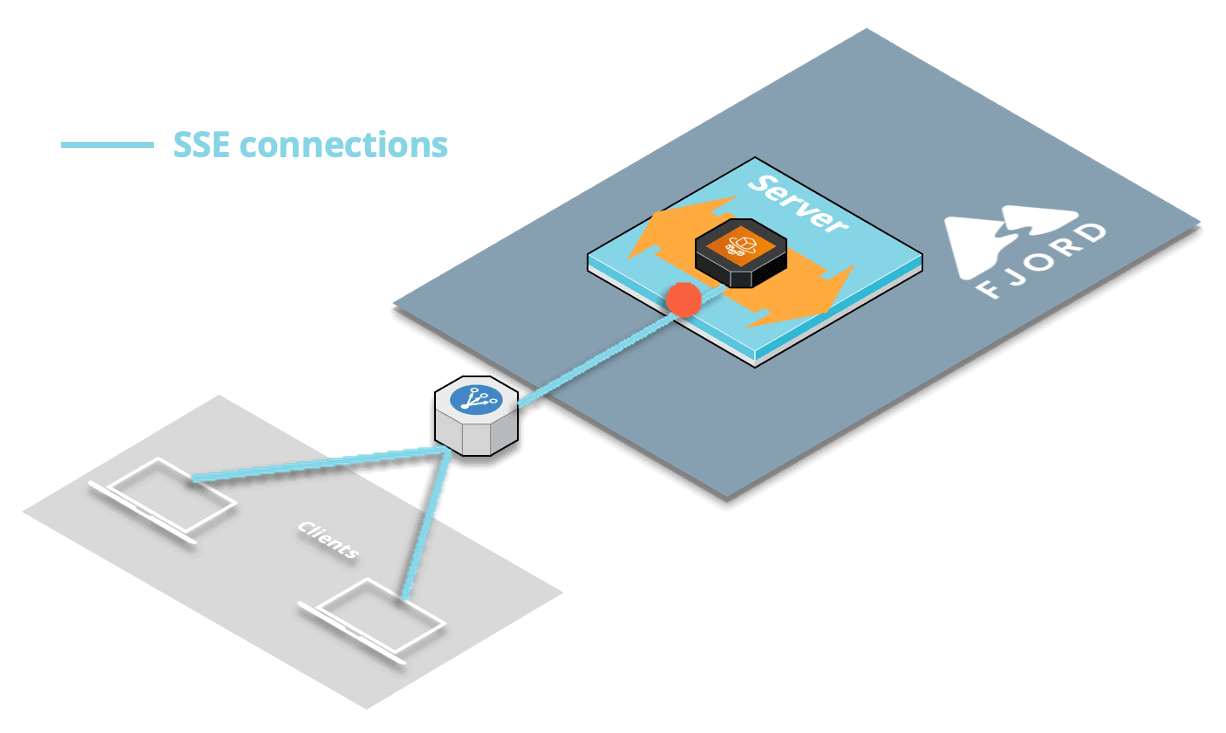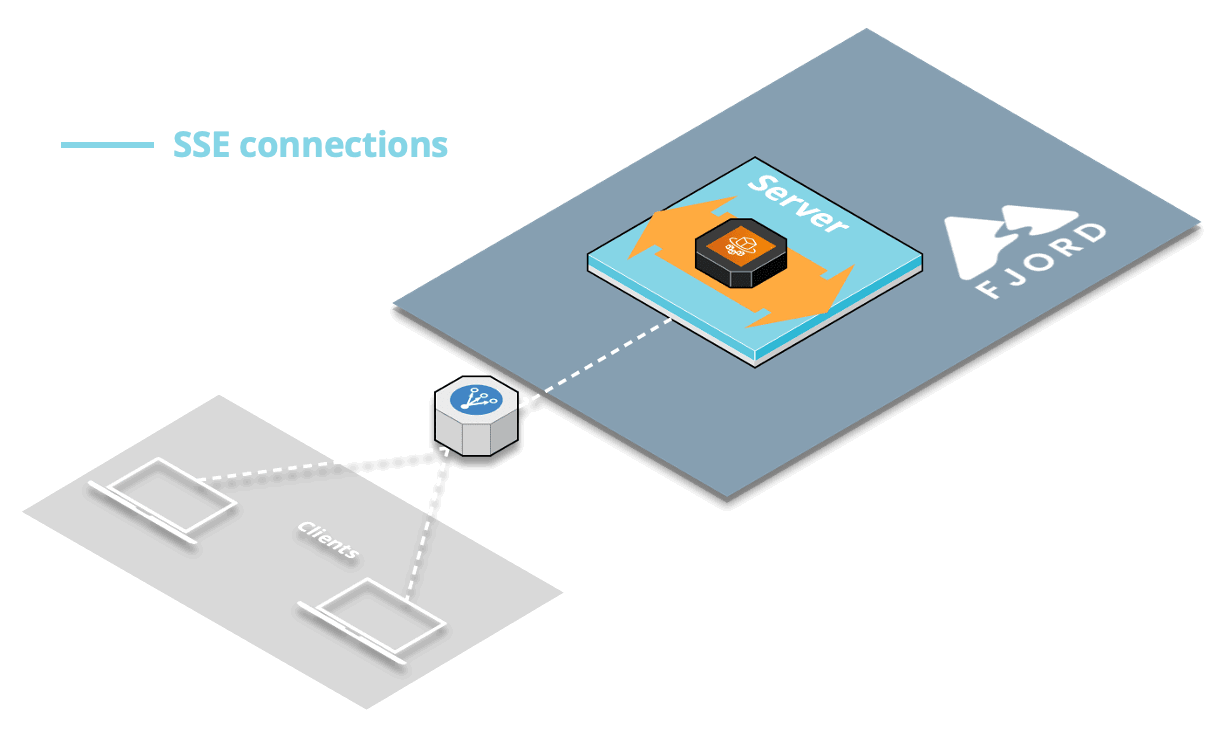
9.2 CORS Issue & Heartbeat
9.2.1 Cross-Origin Requests
A cross-origin request occurs when a page requests access to a resource from a different origin than itself. By default, browsers don’t allow this to happen, as a security measure. By using special request headers, you can explicitly enable Cross-Origin Resource Sharing (or CORS) to allow this to happen.
In our SuperEats example, the SuperEats web servers are delivering an HTML page that makes a request for the Fjord stream. The HTML page is on the SuperEats domain, which is different from the Fjord domain on AWS. For that reason, we knew we’d need to implement CORS. We used the CORS library for Express, since our server is built in Nodejs.
Everything was working fine locally, but we started experiencing some issues when we deployed our code to AWS.
9.2.2 CORS Issue in Production
We noticed that after a brief period of inactivity, when there were no records streaming, clients would get a CORS error displayed on the browser console, and stopped receiving any records.
Things were fine as long as we were regularly streaming records. But once the records stopped for a brief period of time, we’d get a CORS error, and no longer be able to stream even after the records resumed streaming. This was happening despite the fact that we had explicitly enabled CORS via the proper headers.
The issue was that after a period of not receiving any more records, the load balancer would timeout the HTTP responses, thereby forgetting about the headers that had enabled CORS in the first place.
So that’s why we’d get that CORS error.
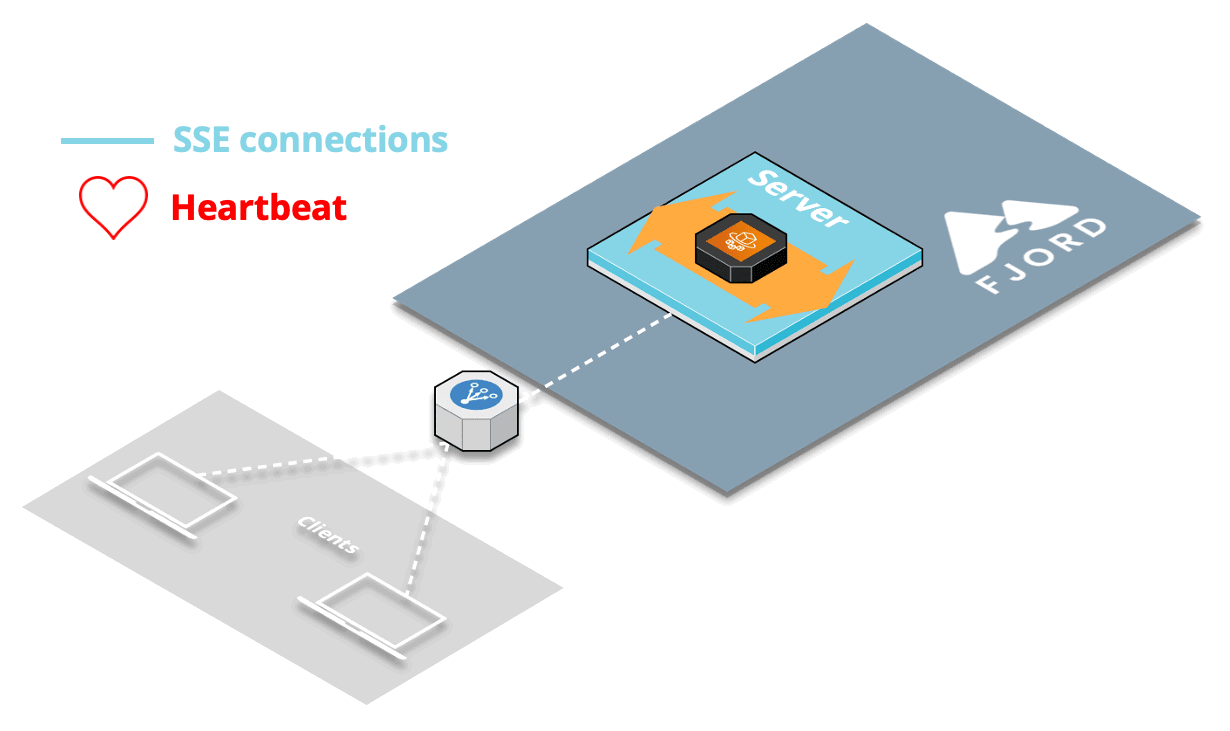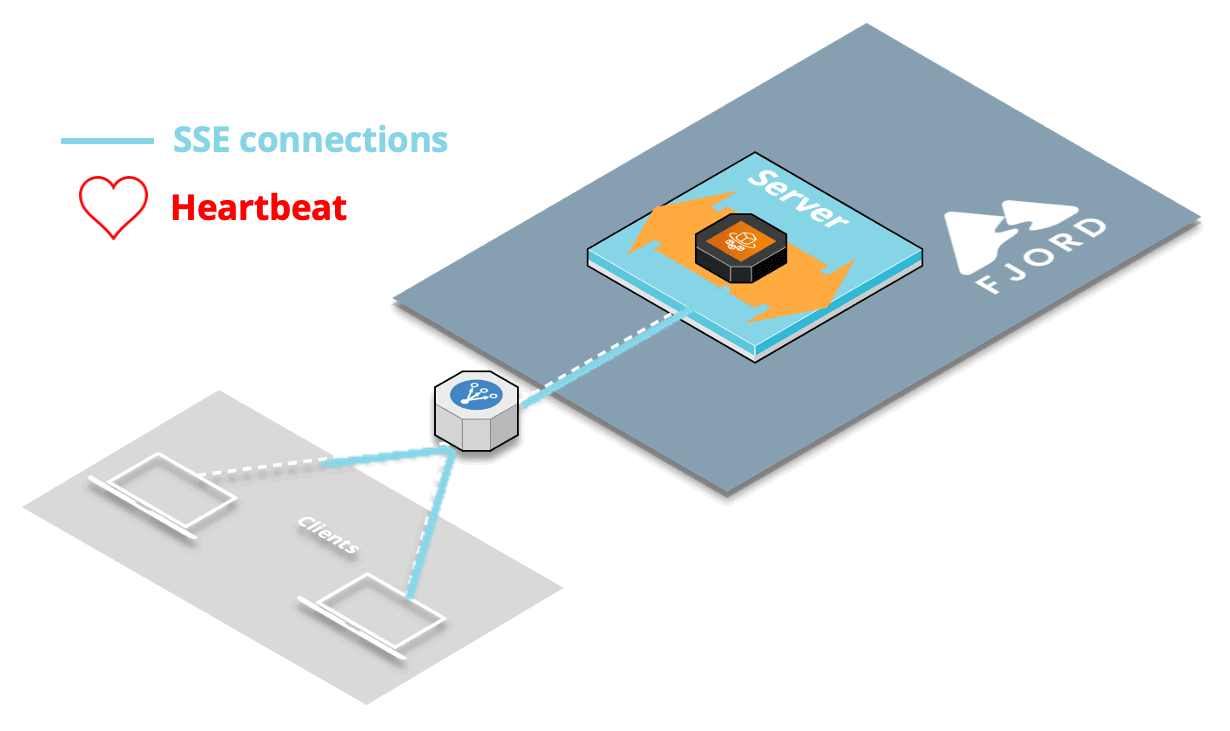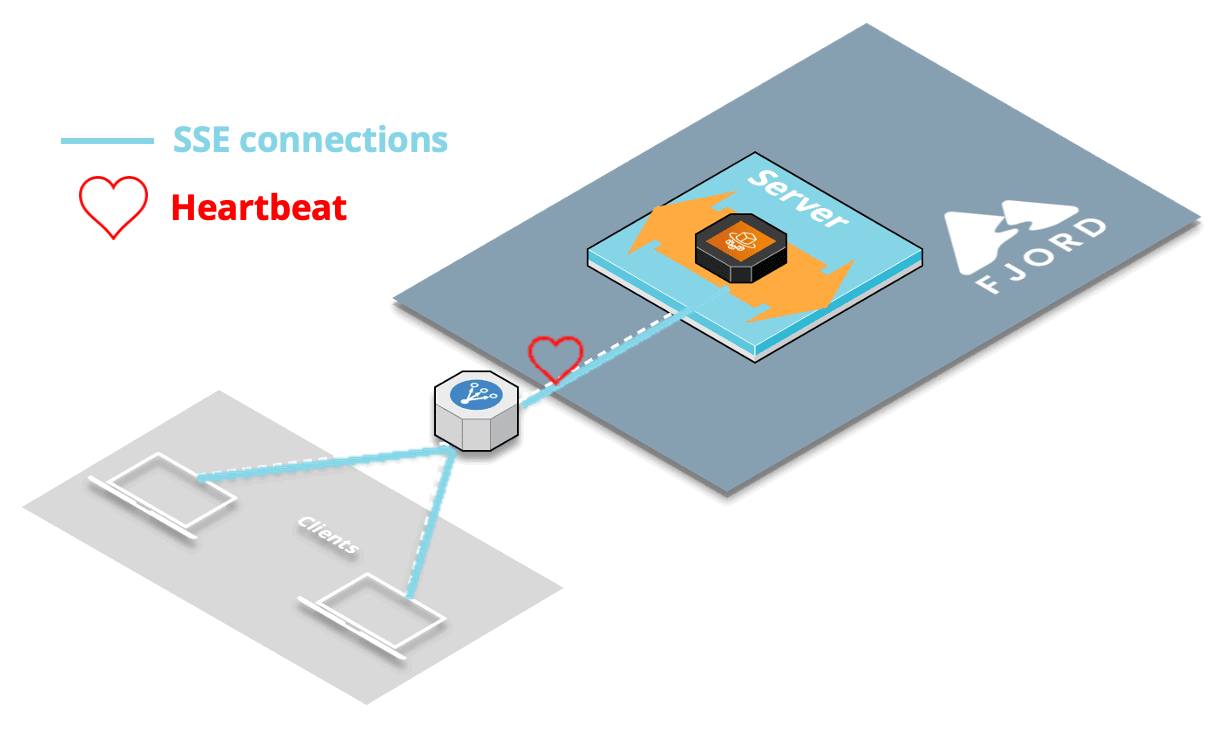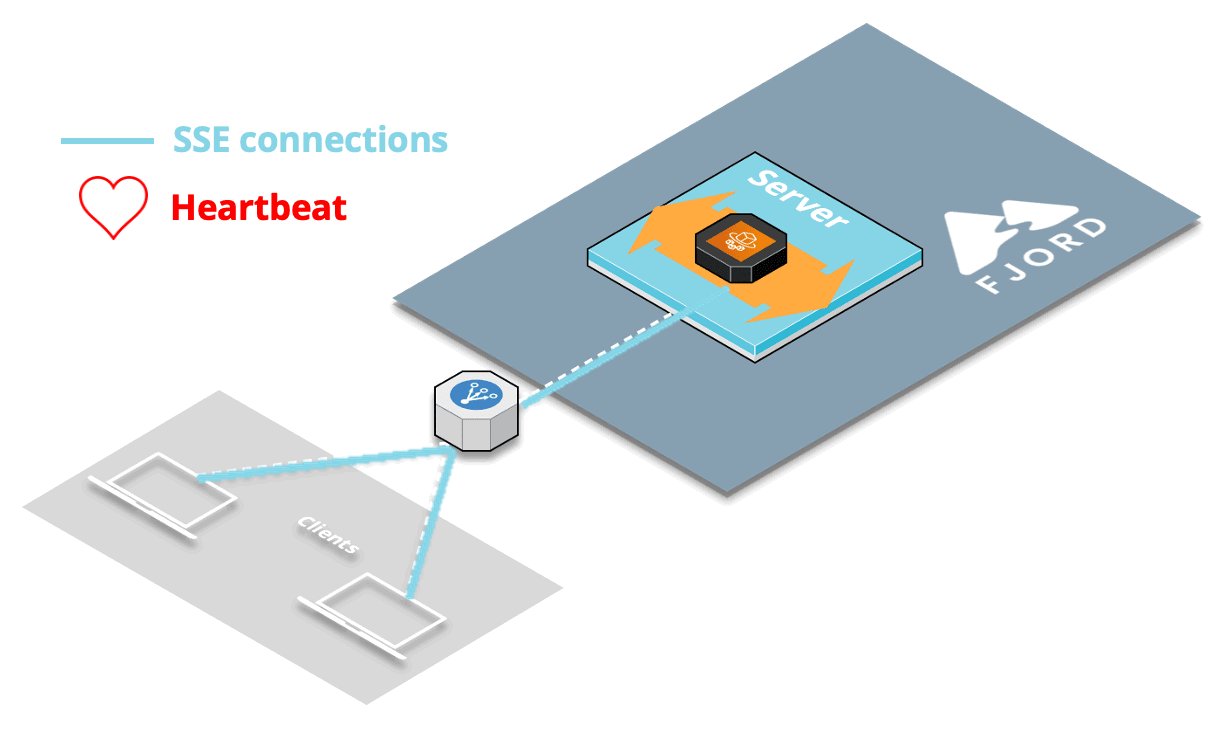
9.2.3 Solution: Heartbeat
The solution to this production-specific issue dealing with the load balancer was to implement what’s known as a heartbeat or “pulse” for SSE.
At a regular interval, about every 30 seconds by default, we send a blank message to all the clients connected to each server. The client doesn’t see this blank message appear anywhere, which is great, but the heartbeat is useful for two main reasons.
First, this checks whether any client has closed the connection since the last time we sent an actual record (and also closes the connection on the server-side if that’s the case). Most importantly for us, this also lets the load balancer know that the connection is still ongoing.
Once we implemented the SSE heartbeat, we no longer had any CORS issues.
9.3 Load Testing Fjord
There are two opening points in the Fjord architecture. First, the Fjord consumer pulls in streams of Kafka data from the business’s Kafka cluster. Second, the Fjord server pushes Kafka data to end users in the browser. While we did perform some stress testing on how many records Fjord could handle per second, we decided this was not the primary point to test. We built Fjord with the intent to stream information that’s usable for connected clients--a maximum dictated by the limits of human perception to a relatively low number. We assume the streaming data the business wants to deliver is about ten messages per second, which the Fjord consumer and Elasticache for Redis are able to handle easily.
The second opening point into Fjord is the load balancer that sits in front of the scalable layer of servers that maintain SSE connections with clients. As business users may want to stream data to thousands or tens of thousands of customers and contract employees with traffic varying immensely depending on the time of day, the Fjord server needs to be able to handle bursty traffic, with some down periods and some periods with vast amounts of traffic.
With our use case in mind, we focused load testing on the frontend of the system--the number of connections the Fjord server could maintain simultaneously.
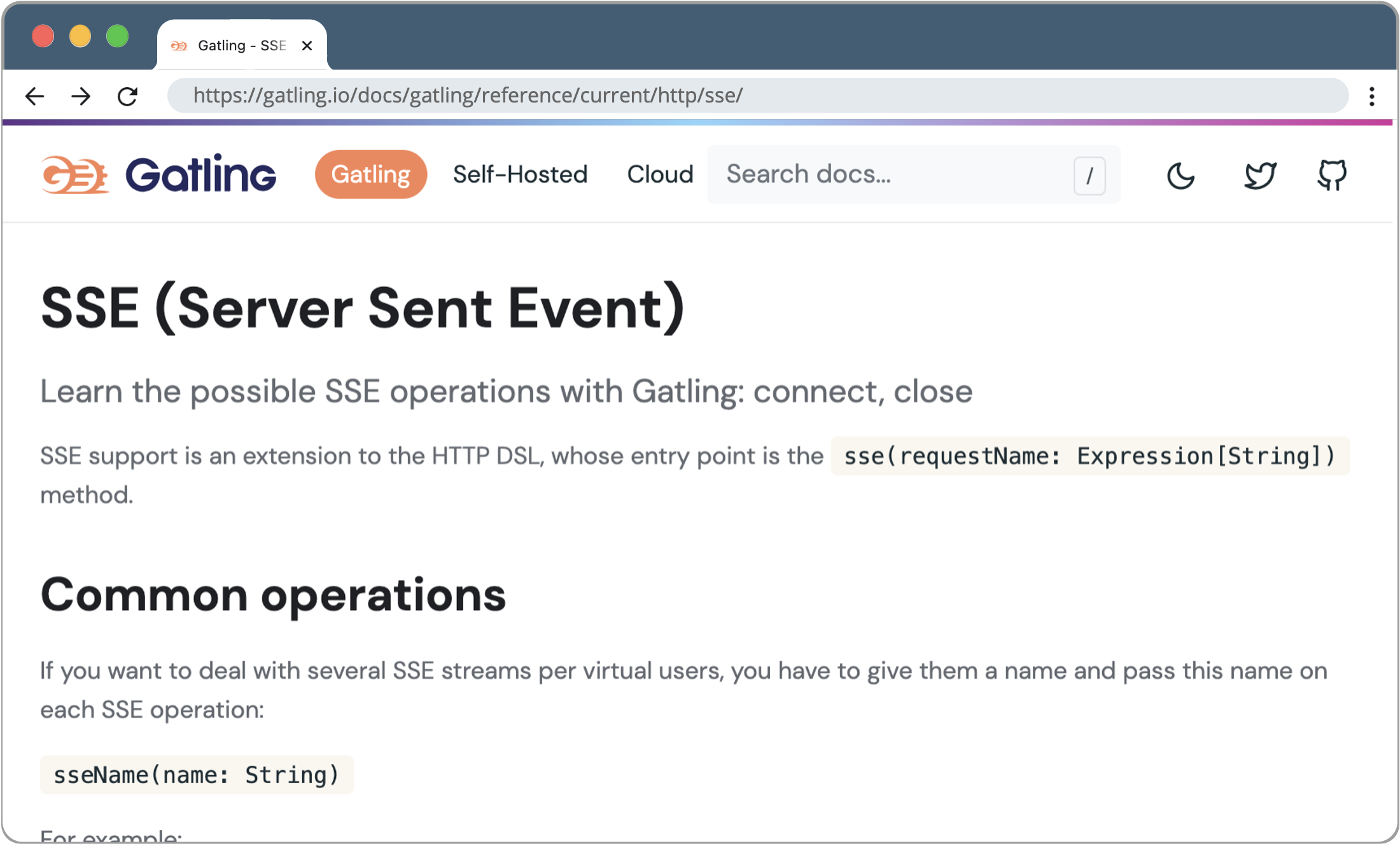
When searching for a load testing tool, we first had a hard time finding an open-source library that worked with Server-Sent-Events. There were several options for load testing Websockets, like Artillery and Siege, but not as many options for SSE.
We eventually came across Gatling, which actually had some good docs for testing SSE. Gatling is built on top of Java and Scala, which did entail learning and working with some Scala. We used Gatling to test what load an individual server could handle.
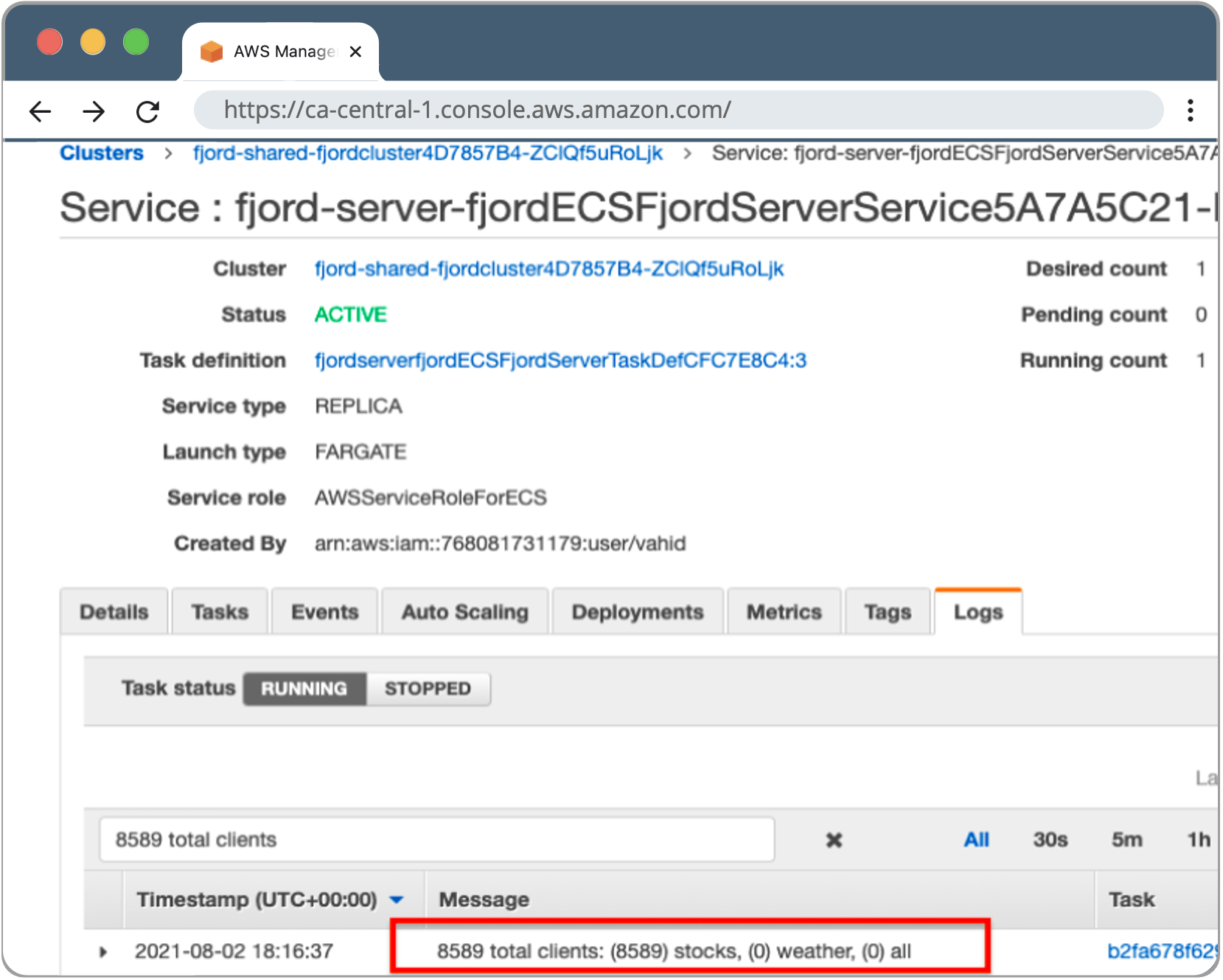
We found that before scaling out, a single server can hold SSE connections for up to 8,500 simultaneous requests.
Fjord servers use the minimal CPU and memory offered by AWS as a cost savings measure for the business user, to ensure that spend is limited to how much use the system is seeing, and no more than that.
Rather than trying to vertically scale an individual Fjord server that would maintain a larger number of SSE connections, we simply had the AWS autoscaling policy spin up or down new instances as needed.
10. Future Work
Fjord is an evolving open source project, with the potential for additional features in the future. We see a few particular improvements and optimizations we’d like to make with Fjord.
10.1 More Advanced Security Features
The Fjord consumer currently connects to a business’s Kafka cluster using a SASL-plain username and password. Kafka offers more advanced security features, including encrypting communication using SSL, making use of network access control lists, and encrypting data at rest, and it would be ideal for Fjord to integrate with more of Kafka’s security options.
10.2 Bidirectional Communication
Fjord is designed with one-way, server push streaming in mind. While this setup is a perfect fit for our use case, we could see the appeal of a bidirectional flow of events.
With tighter Kafka security accomplished with point 10.1 above, we would feel better about allowing the business user to also inject events into their Kafka stream based on client actions.
This could be done with either WebSockets or SSE over HTTP2.
To allow this to happen, we would need a similar architecture to the process of consuming records from Kafka, but reversed. Once the servers receive data from the clients, they would then be publishers to the Redis pubsub middleware. We would need another service deployed on ECS with Fargate, this time to be producers to a Kafka cluster.
Each producer would subscribe to the Redis pubsub, and push every received record to Kafka. We could allow the business user to customize how many producers they want, perhaps based on some type of key added to the record by either the server or the front-end.
Presentation
Meet our team
We are currently looking for opportunities. If you liked what you
saw and want to talk more, please reach out!









 Letting end users connect directly to Kafka would present some significant security risks. Using a proxy provides an additional layer of security in between end users and your Kafka cluster.
Letting end users connect directly to Kafka would present some significant security risks. Using a proxy provides an additional layer of security in between end users and your Kafka cluster.
 An API proxy allows you to fanout Kafka records to thousands of end users over HTTP, significantly reducing the number of direct connections to your Kafka cluster. Using a proxy also allows you to dynamically scale the servers up and down to respond to external user traffic.
An API proxy allows you to fanout Kafka records to thousands of end users over HTTP, significantly reducing the number of direct connections to your Kafka cluster. Using a proxy also allows you to dynamically scale the servers up and down to respond to external user traffic.
 Having an additional layer between Kafka and end users enables more customizations, so you can group various Kafka topics from different Kafka clusters into any number of API end-points with any custom names you want.
Having an additional layer between Kafka and end users enables more customizations, so you can group various Kafka topics from different Kafka clusters into any number of API end-points with any custom names you want.
 This additional messaging layer allows you to offload the resource-intensive task of real-time streaming to an external infrastructure, so you can focus on value creation activities that are central to your business.
This additional messaging layer allows you to offload the resource-intensive task of real-time streaming to an external infrastructure, so you can focus on value creation activities that are central to your business.